Time Series Utilities¶
The fusionlab.utils.ts_utils module provides a collection of
utility functions designed to facilitate common time series data
manipulation, analysis, and preprocessing tasks. These functions can
be helpful when preparing data for use with fusionlab’s
forecasting models or for general time series analysis workflows.
Datetime Handling & Filtering¶
These utilities focus on converting, validating, and filtering time series data based on its datetime index or columns.
filter_by_period¶
- API Reference:
Purpose: To filter rows in a Pandas DataFrame based on whether their datetime values fall within specified evaluation periods (e.g., specific years, months, days, weeks).
Functionality:
Datetime Validation: Ensures the specified
dt_col(or the DataFrame index) is a proper Pandas datetime format, using the internalts_validator().Period Granularity: Detects the granularity (year, month, day, week) from the format of strings in
eval_periods.Filtering: Selects rows where the formatted datetime column matches any period in
eval_periods.Conceptually:
\[\text{filtered}_df = df[\text{format}(dt_{col}).isin(\text{eval}_{periods})]\]where \(\text{format}\) depends on the detected granularity.
Usage Context: Useful for selecting specific time slices of your data for analysis, evaluation, or creating specific training/test sets (e.g., evaluating only on specific months across multiple years).
Code Example:
1import pandas as pd
2from fusionlab.utils.ts_utils import filter_by_period
3
4# Create dummy data
5date_rng = pd.date_range('2022-11-01', periods=100, freq='MS') # Monthly
6df = pd.DataFrame({'Date': date_rng, 'Value': range(100)})
7
8# Filter for specific months across years
9eval_p = ['2023-01', '2024-01', '2023-05']
10filtered_df = filter_by_period(df, eval_periods=eval_p, dt_col='Date')
11
12print("Original DataFrame length:", len(df))
13print(f"Filtered DataFrame for periods {eval_p}:")
14print(filtered_df)
15# Expected output contains only rows for 2023-01, 2024-01, 2023-05
to_dt¶
- API Reference:
Purpose: To robustly convert a specific column or the index of a
Pandas DataFrame into the standard Pandas datetime format
(Timestamp or DatetimeIndex).
It includes special handling for columns/indices containing integer
representations of dates (like years).
Functionality:
Takes DataFrame df and optional dt_col name (defaults to index).
Uses
pandas.to_datetime()for conversion, passing extra arguments.Integer Handling: If the target column/index has an integer dtype, it’s first converted to string to allow correct parsing by pd.to_datetime (especially useful for year integers).
Error Handling: Manages conversion errors based on the error parameter.
Returns the modified DataFrame (and optionally the column name).
Usage Context: An essential utility for standardizing date/time columns
or indices early in your preprocessing pipeline, ensuring compatibility
with Pandas time series operations and other fusionlab functions.
Code Example:
1import pandas as pd
2from fusionlab.utils.ts_utils import to_dt
3
4# DataFrame with date as string and year as integer
5data = {
6 'DateStr': ['2023-01-15', '2023-02-10', '2023-03-20'],
7 'YearInt': [2023, 2024, 2025],
8 'Value': [1, 2, 3]
9}
10df = pd.DataFrame(data)
11print("--- Original dtypes ---")
12print(df.dtypes)
13
14# Convert 'DateStr' column
15df_dt_col = to_dt(df.copy(), dt_col='DateStr')
16# Convert 'YearInt' column (needs format)
17df_dt_year = to_dt(df.copy(), dt_col='YearInt', format='%Y')
18
19print("\n--- dtypes after to_dt('DateStr') ---")
20print(df_dt_col.dtypes)
21print("\n--- dtypes after to_dt('YearInt') ---")
22print(df_dt_year.dtypes)
ts_split¶
- API Reference:
Purpose: To split time series data into training and testing sets while respecting chronological order, or to generate time-series-aware cross-validation splits. This prevents lookahead bias.
Functionality:
Takes a DataFrame df and parameters controlling the split type.
split_type=’simple’: Performs a single chronological split.
Date-Based: Splits using train_start/train_end dates.
Ratio-Based: Splits using test_ratio, taking the last fraction as the test set. Conceptually, splits at \(k = N \times (1 - \text{test_ratio})\):
\[\text{Train} = \{X_t | t \le k \}, \quad \text{Test} = \{X_t | t > k \}\]Returns (train_df, test_df).
split_type=’cv’: Creates time series cross-validation splits using
sklearn.model_selection.TimeSeriesSplit.Generates n_splits pairs of (train_indices, test_indices).
Uses expanding windows by default.
Supports a gap between train and test sets.
Returns a generator yielding index pairs.
Usage Context: Essential for evaluating time series models correctly. Use ‘simple’ for hold-out validation. Use ‘cv’ for robust cross-validation performance estimation and hyperparameter tuning. Requires scikit-learn for ‘cv’.
Code Examples:
Example 1: Simple Ratio Split
1import pandas as pd
2# Assuming ts_split is importable
3from fusionlab.utils.ts_utils import ts_split
4
5# Dummy time series data
6dates = pd.date_range('2023-01-01', periods=100)
7df = pd.DataFrame({'Date': dates, 'Value': range(100)})
8
9# Split: 70% train, 30% test
10train_df, test_df = ts_split(
11 df,
12 dt_col='Date', # Ensure data is sorted by this
13 split_type='simple',
14 test_ratio=0.3
15)
16print("--- Simple Split ---")
17print(f"Train shape: {train_df.shape}") # Expected (70, 2)
18print(f"Test shape: {test_df.shape}") # Expected (30, 2)
19print(f"Last train date: {train_df['Date'].iloc[-1]}")
20print(f"First test date: {test_df['Date'].iloc[0]}")
Example 2: Time Series Cross-Validation
1import pandas as pd
2# Assuming ts_split is importable
3from fusionlab.utils.ts_utils import ts_split
4
5# Dummy time series data
6dates = pd.date_range('2023-01-01', periods=20)
7df = pd.DataFrame({'Date': dates, 'Value': range(20)})
8
9n_cv_splits = 3
10cv_splits_generator = ts_split(
11 df,
12 dt_col='Date',
13 split_type='cv',
14 n_splits=n_cv_splits
15)
16
17print("\n--- Cross-Validation Splits ---")
18for i, (train_index, test_index) in enumerate(cv_splits_generator):
19 print(f"Fold {i+1}:")
20 print(f" Train indices: {train_index}")
21 print(f" Test indices: {test_index}")
22 # Example usage:
23 # X_train_fold, X_test_fold = df.iloc[train_index], df.iloc[test_index]
ts_outlier_detector¶
- API Reference:
Purpose: To identify potential outliers within a specified time series column (value_col) using standard statistical methods (Z-Score or IQR). Optionally removes detected outliers.
Functionality:
Uses one of two methods based on the method parameter:
method=’zscore’: Calculates Z-scores (\(Z_t = (X_t - \mu)/\sigma\)). Flags points where \(|Z_t| > \text{threshold}\) (default 3). Assumes approximate normality.
method=’iqr’: Uses Interquartile Range (\(IQR = Q3 - Q1\)). Calculates bounds: Lower = \(Q1 - \text{threshold} \times IQR\), Upper = \(Q3 + \text{threshold} \times IQR\). Flags points outside these bounds (default threshold 1.5). More robust to skewed data.
The function adds an 'is_outlier' boolean column. If drop=True,
outlier rows are removed instead. If view=True, shows a plot.
Usage Context: A data cleaning step to find or remove anomalous points that might distort analysis or model training. Requires scipy for Z-score.
Code Example:
1import pandas as pd
2import numpy as np
3from fusionlab.utils.ts_utils import ts_outlier_detector
4
5# Dummy data with outliers
6data = {
7 'Time': pd.to_datetime(pd.date_range('2023-01-01', periods=20)),
8 'Value': np.random.randn(20) * 5 + 50
9}
10df = pd.DataFrame(data)
11# Add outliers
12df.loc[5, 'Value'] = 150
13df.loc[15, 'Value'] = -20
14
15print("--- Original Data (Snippet) ---")
16print(df.iloc[[4,5,6, 14,15,16]])
17
18# Detect outliers using Z-score (keep them, add column)
19df_flagged = ts_outlier_detector(
20 df,
21 value_col='Value',
22 method='zscore',
23 threshold=2.0, # Lower threshold to catch outliers
24 drop=False
25)
26print("\n--- Data with Outliers Flagged ---")
27print(df_flagged[df_flagged['is_outlier']])
28
29# Detect and drop outliers using IQR
30df_dropped = ts_outlier_detector(
31 df,
32 value_col='Value',
33 method='iqr',
34 threshold=1.5,
35 drop=True # Remove outlier rows
36)
37print(f"\n--- Data Shape After Dropping Outliers ---")
38print(f"Original shape: {df.shape}, Dropped shape: {df_dropped.shape}")
Trend & Seasonality Analysis¶
These utilities help in analyzing, decomposing, transforming, and visualizing trends and seasonal patterns within time series data, often leveraging the statsmodels library.
trend_analysis¶
- API Reference:
Purpose: To perform a basic analysis of a time series to identify its overall trend direction (upward, downward, or stationary) and optionally assess its stationarity using statistical tests (ADF or KPSS).
Functionality:
Stationarity Test (Optional): If
check_stationarity=True, performs ADF (Null: Non-stationary) or KPSS (Null: Stationary) test.Linear Trend Fitting: If needed (based on test or
trend_type), fits a linear OLS model: \(y_t = \beta_0 + \beta_1 \cdot t + \epsilon_t\).Trend Classification: Classifies trend based on stationarity test p-value and the OLS slope (\(\beta_1\)).
Visualization (Optional): If
view=True, plots the series, test results, and the fitted trend/mean line.
Usage Context: A useful first step in EDA for a quick assessment
of stationarity and linear trend, guiding subsequent preprocessing like
detrending (transform_stationarity()) or differencing.
Requires statsmodels.
Code Example:
1import numpy as np
2import pandas as pd
3# Assuming trend_analysis is importable
4from fusionlab.utils.ts_utils import trend_analysis
5
6# Create dummy data: upward trend
7dates = pd.date_range('2023-01-01', periods=50)
8values_up = np.linspace(10, 50, 50) + np.random.randn(50) * 2
9df_up = pd.DataFrame({'Date': dates, 'Value': values_up})
10
11# Analyze the trend (using ADF test)
12trend, p_value, _ = trend_analysis(
13 df_up,
14 value_col='Value',
15 dt_col='Date',
16 check_stationarity=True,
17 strategy='adf',
18 view=False # Keep docs build clean
19)
20print(f"--- Upward Trend Analysis ---")
21print(f"Detected Trend: {trend}")
22print(f"ADF p-value: {p_value:.4f}") # Likely high -> Non-stationary
23
24# Create stationary data
25values_stat = 5 + np.random.randn(50)
26df_stat = pd.DataFrame({'Date': dates, 'Value': values_stat})
27
28# Analyze stationary trend
29trend_s, p_value_s, _ = trend_analysis(
30 df_stat, value_col='Value', dt_col='Date', strategy='adf', view=False
31)
32print(f"\n--- Stationary Analysis ---")
33print(f"Detected Trend: {trend_s}")
34print(f"ADF p-value: {p_value_s:.4f}") # Likely low -> Stationary
trend_ops¶
- API Reference:
Purpose: To apply specific transformations aimed at removing or
mitigating trends based on an automatic trend analysis performed
internally using trend_analysis().
Functionality:
Trend Detection: Calls
trend_analysis()to find the trend (‘upward’, ‘downward’, ‘stationary’).Transformation: Based on detected trend and specified ops:
‘remove_upward’, ‘remove_downward’, ‘remove_both’: If trend matches, subtracts the fitted OLS linear trend \(Y'_{t} = Y_t - \hat{Y}_t\).
‘detrend’: If ‘non-stationary’ detected, applies first-order differencing \(\nabla Y_t = Y_t - Y_{t-1}\).
‘none’: No transformation.
Update: Modifies the value_col in the DataFrame in-place (or returns a modified copy depending on implementation details).
Usage Context: Automates making a time series (more) stationary
by removing identified linear trends or applying differencing. Useful
preprocessing for classical models (e.g., ARIMA). Requires statsmodels.
Code Example:
1import numpy as np
2import pandas as pd
3import matplotlib.pyplot as plt
4from fusionlab.utils.ts_utils import trend_ops
5
6# Create dummy data with upward trend
7dates = pd.date_range('2023-01-01', periods=50)
8values_up = np.linspace(10, 50, 50) + np.random.randn(50) * 2
9df_up = pd.DataFrame({'Date': dates, 'Value': values_up})
10df_up_copy = df_up.copy() # Work on a copy
11
12# Remove the upward trend
13# Note: trend_ops likely modifies inplace or returns df
14df_detrended = trend_ops(
15 df_up_copy,
16 value_col='Value',
17 dt_col='Date',
18 ops='remove_upward', # or 'detrend' for differencing
19 check_stationarity=True, # Allow it to detect trend first
20 view=False # Set True to see plots locally
21)
22
23print("--- Trend Removal Example ---")
24print("Original Data Head:")
25print(df_up.head(3))
26print("\nDetrended Data Head (linear trend removed):")
27print(df_detrended.head(3)) # Note: Check if inplace or returns copy
28
29# Optional: Simple plot to visualize
30# plt.figure()
31# plt.plot(df_up['Date'], df_up['Value'], label='Original')
32# plt.plot(df_detrended['Date'], df_detrended['Value'], label='Detrended')
33# plt.legend(); plt.show()
visual_inspection¶
- API Reference:
visual_inspection()
Purpose: To generate a comprehensive set of diagnostic plots for visually exploring the characteristics of a time series, including trend, seasonality, autocorrelation, and decomposition components.
Functionality:
Creates a matplotlib grid displaying:
Original Time Series: Plot of raw data.
Rolling Mean (Trend): Optional plot of rolling mean over window. Helps visualize trend. \(\text{RollingMean}_t = \frac{1}{W}\sum_{i=0}^{W-1} X_{t-i}\)
Rolling Std Dev: Optional plot of rolling standard deviation. Can indicate changing volatility or seasonality.
ACF Plot: Optional Autocorrelation Function plot up to lags.
Seasonal Decomposition: Optional plot of Observed, Trend, Seasonal, Residual components using statsmodels classical decomposition (requires seasonal_period).
Usage Context: An essential EDA tool providing quick visual insights
into time series properties to inform modeling and preprocessing choices.
Requires statsmodels and matplotlib.
Code Example (Call Only):
(Note: This function primarily generates plots. Running this will display the plots if run interactively, but output is not captured here.)
1import numpy as np
2import pandas as pd
3from fusionlab.utils.ts_utils import visual_inspection
4
5# Create dummy data with trend and seasonality
6dates = pd.date_range('2020-01-01', periods=100, freq='D')
7trend = np.linspace(0, 10, 100)
8seasonal = 5 * np.sin(2 * np.pi * dates.dayofyear / 7) # Weekly pattern
9noise = np.random.randn(100) * 2
10values = trend + seasonal + noise
11df = pd.DataFrame({'Date': dates, 'Value': values})
12
13print("Calling visual_inspection (plots will be generated)...")
14# Example call showing various plots
15visual_inspection(
16 df,
17 value_col='Value',
18 dt_col='Date',
19 window=7, # Rolling window size
20 lags=20, # ACF lags
21 seasonal_period=7, # For decomposition
22 show_trend=True,
23 show_seasonal=True,
24 show_acf=True,
25 show_decomposition=True,
26)
27print("Visual inspection call complete.")
Expected Output:
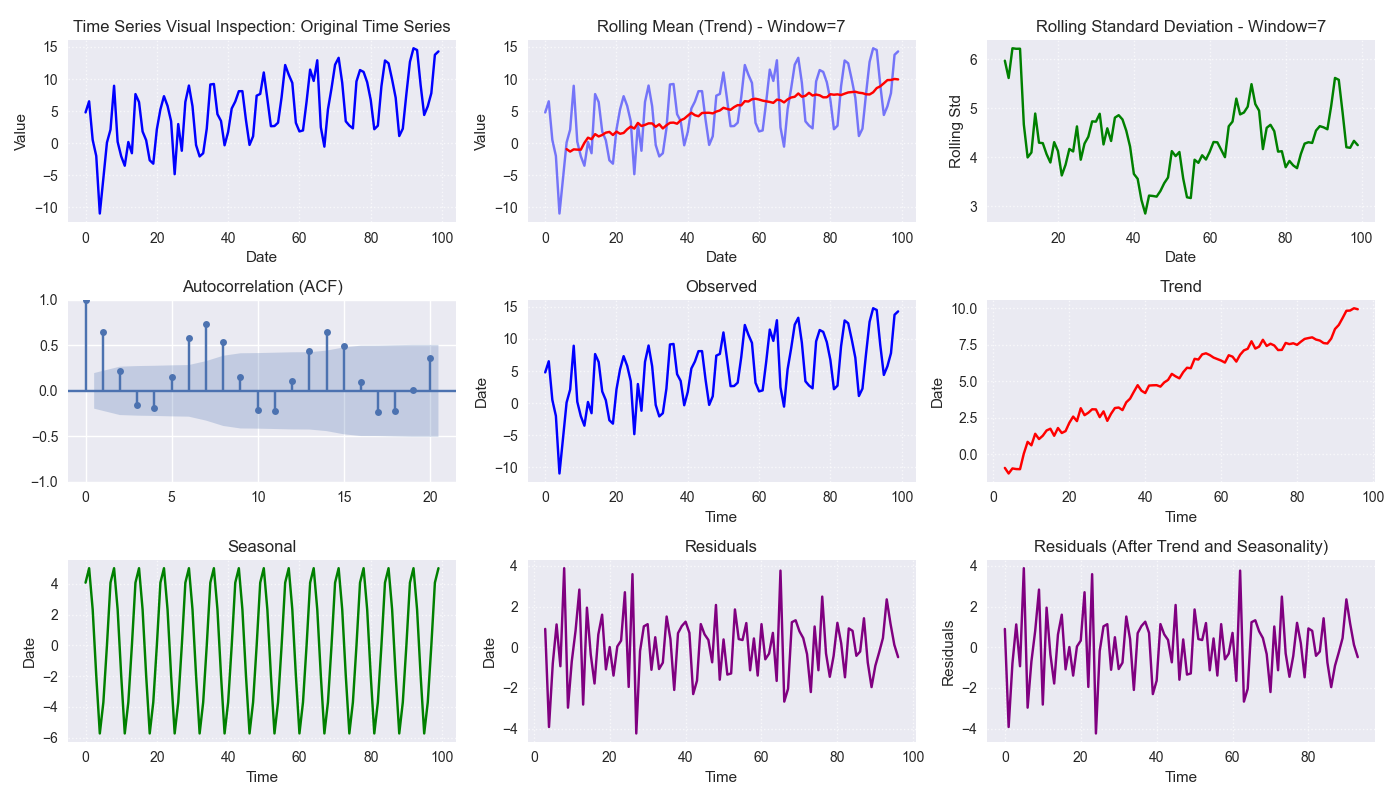
Plot visual panels for time-series analysis including decomposition.¶
get_decomposition_method¶
- API Reference:
Purpose: To provide a heuristic estimate of a suitable decomposition model type (‘additive’ or ‘multiplicative’) and a basic guess for the seasonal period.
Functionality:
Takes DataFrame df, value_col.
Method Inference (`method=’auto’`): Suggests ‘multiplicative’ if all values > 0, otherwise suggests ‘additive’. Can be overridden.
Period Inference: Uses very basic logic (returns 1 or min_period). Not reliable for finding true seasonality.
Usage Context: A quick, rule-based first guess for decomposition parameters, mainly distinguishing additive/multiplicative based on positivity. Limited utility for period detection.
Code Example:
1import pandas as pd
2from fusionlab.utils.ts_utils import get_decomposition_method
3
4# Data with positive values
5df_pos = pd.DataFrame({'Value': [10, 12, 15, 13]})
6method1, period1 = get_decomposition_method(df_pos, 'Value', method='auto')
7print(f"Positive Data -> Method: {method1}, Period: {period1}")
8# Expected: multiplicative, 1 (or min_period)
9
10# Data with non-positive values
11df_nonpos = pd.DataFrame({'Value': [10, -2, 15, 0]})
12method2, period2 = get_decomposition_method(df_nonpos, 'Value', method='auto')
13print(f"Non-Positive Data -> Method: {method2}, Period: {period2}")
14# Expected: additive, 1 (or min_period)
infer_decomposition_method¶
- API Reference:
Purpose: To determine the more appropriate decomposition method (‘additive’ or ‘multiplicative’) using either a positivity heuristic or by comparing residual variances from both decomposition types.
Functionality:
Takes df, dt_col, required period.
`method=’heuristic’`: Checks if all values > 0. Returns ‘multiplicative’ or ‘additive’.
`method=’variance_comparison’`: Performs both additive and multiplicative decomposition (statsmodels) using the given period. Calculates residual variance (\(Var(\epsilon_t)\)) for both. Returns the method (‘additive’/’multiplicative’) with the lower residual variance. Optionally plots residual histograms (view=True) or returns components (return_components=True).
Usage Context: A more data-driven approach (variance comparison)
than the simple heuristic for choosing between models, assuming the
correct period is known. Requires statsmodels.
Code Example:
1import numpy as np
2import pandas as pd
3# Assuming infer_decomposition_method is importable
4from fusionlab.utils.ts_utils import infer_decomposition_method
5
6# Create dummy data (e.g., additive seasonality)
7dates = pd.date_range('2020-01-01', periods=48, freq='MS')
8trend = np.linspace(50, 100, 48)
9seasonal = 10 * np.sin(2 * np.pi * dates.month / 12)
10noise = np.random.randn(48) * 2
11values = trend + seasonal + noise
12df = pd.DataFrame({'Date': dates, 'Value': values})
13
14# Infer method using variance comparison (requires period)
15seasonal_period = 12
16best_method = infer_decomposition_method(
17 df,
18 dt_col='Date',
19 value_col= 'Value', # value col must be specified as kwarg argument
20 period=seasonal_period,
21 method='variance_comparison',
22 view=False # Set True to see plots
23)
24print(f"--- Decomposition Method Inference ---")
25print(f"Data designed as additive.")
26print(f"Best method by variance comparison: '{best_method}'")
27# Expected: Often 'additive' for this data, but noise can influence
Expected Output:

Decomposition method inferred.¶
decompose_ts¶
- API Reference:
Purpose: To perform time series decomposition, separating a series (value_col) into Trend (\(T_t\)), Seasonal (\(S_t\)), and Residual (\(R_t\)) components using statsmodels methods (STL or classical SDT).
Functionality:
Takes df, value_col, optional dt_col, method (‘additive’ or ‘multiplicative’ for SDT), strategy (‘STL’ or ‘SDT’), seasonal_period.
Selects Algorithm:
‘STL’: Uses statsmodels.tsa.seasonal.STL (robust, flexible).
‘SDT’: Uses statsmodels.tsa.seasonal.seasonal_decompose (classical additive/multiplicative).
Performs decomposition using the specified seasonal_period.
Returns input DataFrame augmented with ‘trend’, ‘seasonal’, and ‘residual’ columns.
Mathematical Models:
Additive: \(Y_t = T_t + S_t + R_t\)
Multiplicative: \(Y_t = T_t \times S_t \times R_t\)
Usage Context: Explicitly extracts and adds decomposition components
to your DataFrame for analysis, visualization, separate forecasting, or
use as features. Requires statsmodels.
Code Example:
1import numpy as np
2import pandas as pd
3from fusionlab.utils.ts_utils import decompose_ts
4
5# Create dummy data (use data from infer_decomposition_method)
6dates = pd.date_range('2020-01-01', periods=48, freq='MS')
7trend = np.linspace(50, 100, 48)
8seasonal = 10 * np.sin(2 * np.pi * dates.month / 12)
9noise = np.random.randn(48) * 2
10values = trend + seasonal + noise
11df = pd.DataFrame({'Date': dates, 'Value': values})
12
13# Decompose using STL (additive is implicit for STL)
14seasonal_period = 12
15df_decomposed_stl = decompose_ts(
16 df,
17 value_col='Value',
18 dt_col='Date',
19 strategy='STL', # Specify STL strategy
20 seasonal_period=seasonal_period
21)
22
23print("--- STL Decomposition Output ---")
24print(df_decomposed_stl[['Value', 'trend', 'seasonal', 'residual']].head())
25
26# Decompose using classical SDT (additive)
27df_decomposed_sdt = decompose_ts(
28 df,
29 value_col='Value',
30 dt_col='Date',
31 strategy='SDT', # Specify classical strategy
32 method='additive', # Specify model type
33 seasonal_period=seasonal_period
34)
35print("\n--- SDT (Additive) Decomposition Output ---")
36print(df_decomposed_sdt[['Value', 'trend', 'seasonal', 'residual']].head())
transform_stationarity¶
- API Reference:
Purpose: To apply common transformations aimed at achieving or improving time series stationarity (stabilizing mean/variance).
Functionality:
Applies a transformation to value_col based on method:
‘differencing’: Applies differencing of order or uses seasonal_period. \(\nabla Y_t = Y_t - Y_{t-1}\).
‘log’: Applies \(\ln(Y_t)\) (requires \(Y_t > 0\)).
‘sqrt’: Applies \(\sqrt{Y_t}\) (requires \(Y_t \ge 0\)).
`’detrending’`: Removes trend using:
‘linear’: Subtracts OLS linear fit \(Y_t - (\beta_0 + \beta_1 t)\).
‘stl’: Returns residual component \(R_t\) from STL decomposition.
Adds transformed series as '<value_col>_transformed'. Optionally
drops original (drop_original) or plots (view).
Usage Context: Preprocessing step for models assuming stationarity (e.g., ARIMA). Use differencing for trends/seasonality, log/sqrt for variance stabilization. Requires statsmodels for STL detrending.
Code Example:
1import numpy as np
2import pandas as pd
3from fusionlab.utils.ts_utils import transform_stationarity
4
5# Create dummy data with upward trend
6dates = pd.date_range('2023-01-01', periods=50)
7values_up = np.linspace(10, 50, 50)**1.5 # Non-linear trend
8df_up = pd.DataFrame({'Date': dates, 'Value': values_up})
9df_up['Date'] = pd.to_datetime(df_up['Date']) # Ensure datetime
10df_up.set_index('Date', inplace=True)
11
12# Apply first-order differencing
13df_diff = transform_stationarity(
14 df_up.copy(), # Use copy
15 value_col='Value',
16 method='differencing',
17 order=1,
18 view=False
19)
20print("--- Differencing Output ---")
21print(df_diff[['Value_transformed']].head()) # Note NaNs
22
23# Apply log transform (add offset if data can be zero)
24df_log = transform_stationarity(
25 df_up.copy() + 0.01, # Ensure positive for log
26 value_col='Value',
27 method='log',
28 view=False
29)
30print("\n--- Log Transform Output ---")
31print(df_log[['Value_transformed']].head())
32
33# Apply linear detrending
34df_detrend = transform_stationarity(
35 df_up.copy(),
36 value_col='Value',
37 method='detrending',
38 detrend_method='linear',
39 view=True
40)
41print("\n--- Linear Detrending Output ---")
42print(df_detrend[['Value_transformed']].head())
Expected Output:
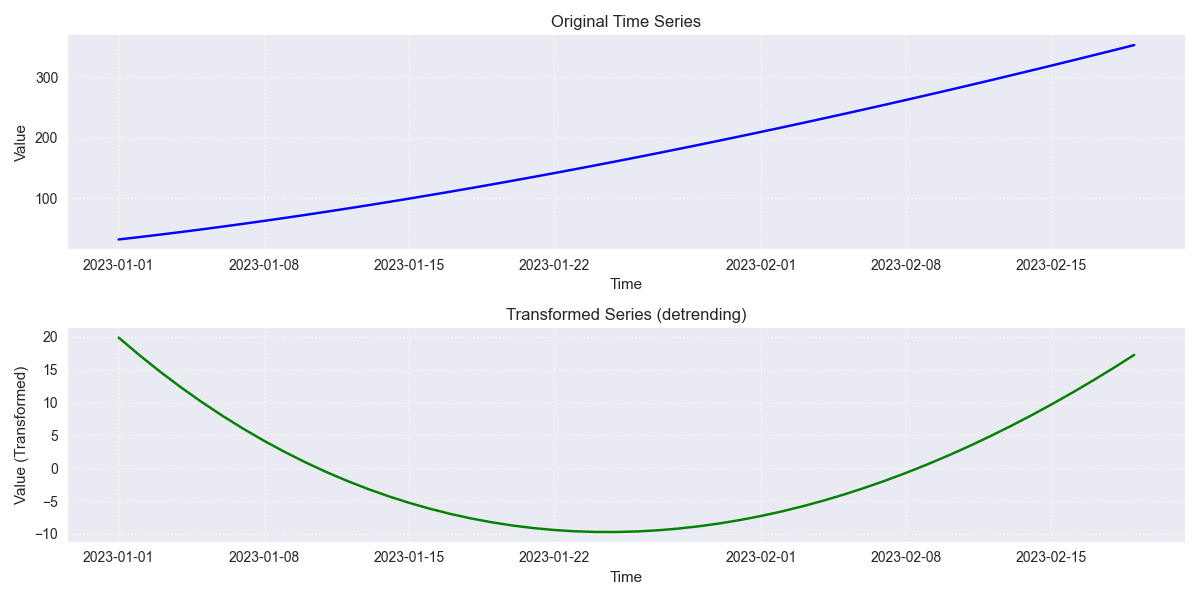
Stationary transformed plot.¶
ts_corr_analysis¶
- API Reference:
Purpose: To analyze and visualize time series correlations: autocorrelation (ACF), partial autocorrelation (PACF), and cross-correlation with external features.
Functionality:
ACF/PACF: Optional plots (view_acf_pacf=True) using statsmodels. ACF: \(\rho(h) = \frac{Cov(Y_t, Y_{t-h})}{\dots}\). Helps identify MA/AR orders for ARIMA.
Cross-Correlation: Calculates Pearson correlation (zero-lag) between value_col and specified features using scipy.stats.pearsonr. Optionally plots results (view_cross_corr=True).
Output: Returns dict with cross-correlation coefficients/p-values.
Usage Context: EDA tool to understand series memory (ACF/PACF) and identify potential external predictors (cross-correlation). Requires statsmodels, scipy, matplotlib.
Code Example (Results Only):
1import pandas as pd
2from fusionlab.utils.ts_utils import ts_corr_analysis
3
4# Dummy data with target and feature
5dates = pd.date_range('2023-01-01', periods=50)
6data = {
7 'Date': dates,
8 'Sales': 50 + np.arange(50)*0.5 + np.random.randn(50)*5,
9 'Promo': np.random.randint(0, 2, 50)
10}
11df = pd.DataFrame(data)
12
13# Perform analysis, get results dict (suppress plots)
14results = ts_corr_analysis(
15 df,
16 dt_col='Date',
17 value_col='Sales',
18 lags=10, # Lags for ACF/PACF calculation (if viewed)
19 features=['Promo'], # Check correlation with Promo
20 view_acf_pacf=True, # False to suppress ACF/PACF plots
21 view_cross_corr=False # Suppress cross-corr plot
22)
23
24print("--- Correlation Analysis Results ---")
25print("Cross-Correlation with 'Promo':")
26print(results['cross_corr'])
27# Note: ACF/PACF values are not returned, only plotted if view=True
Expected Output:
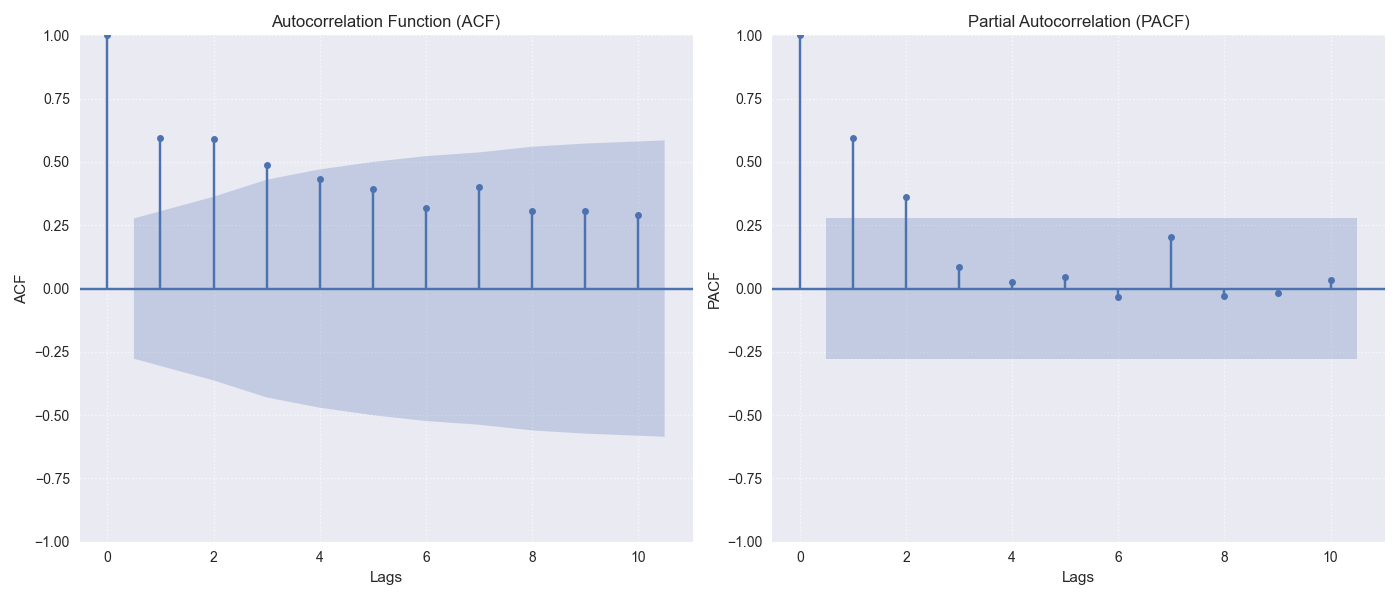
Time-Series Correlation Analysis¶
Feature Engineering¶
These utilities focus on creating new features from time series data that can be beneficial for machine learning models, capturing temporal dependencies, calendar effects, and other patterns.
ts_engineering¶
- API Reference:
Purpose: To automatically generate a variety of common and useful time series features from a DataFrame, augmenting it with predictors that capture temporal dynamics, seasonality, and other patterns.
Functionality: Takes a DataFrame df (with a datetime index or dt_col), the primary value_col, and various parameters:
Time-Based Features: Extracts year, month, day, day_of_week, is_weekend, quarter, hour.
Holiday Indicator: Creates binary ‘is_holiday’ if holiday_df provided.
Lag Features: Creates lags number of lag features (e.g., \(Y_{t-1}, Y_{t-2}\)).
Rolling Statistics: Calculates rolling mean/std dev over window size (\(W\)).
\[\begin{split}\text{RollingMean}_t = \frac{1}{W}\sum_{i=0}^{W-1} Y_{t-i} \\ \text{RollingStd}_t = \sqrt{\frac{1}{W-1}\sum_{i=0}^{W-1} (Y_{t-i} - \text{RollingMean}_t)^2}\end{split}\]Differencing: Creates differenced series of diff_order (\(\nabla Y_t = Y_t - Y_{t-1}\) for order 1).
Seasonal Differencing: Optional differencing at seasonal_period lag \(S\) (\(Y_t - Y_{t-S}\)).
Fourier Features: Optional FFT magnitude features (apply_fourier=True).
NA Handling: Fills NaNs from lags/rolling/diff using ffill, then drops remaining.
Scaling: Optional scaling of numeric features (scaler=’z-norm’ or ‘minmax’).
Usage Context: A powerful utility for automating the creation of a
rich feature set for time series models. The resulting DataFrame can be
used directly or passed to sequence preparation utilities like
create_sequences() or
reshape_xtft_data().
Code Example:
1import pandas as pd
2import numpy as np
3# Assuming ts_engineering is importable
4from fusionlab.utils.ts_utils import ts_engineering
5
6# Create dummy data
7dates = pd.date_range('2023-01-01', periods=20)
8df = pd.DataFrame({'Date': dates, 'Value': np.arange(20) * 2.5 + 10})
9df = df.set_index('Date') # Use datetime index
10
11# Apply feature engineering
12df_featured = ts_engineering(
13 df=df.copy(), # Pass a copy
14 value_col='Value',
15 lags=2,
16 window=3,
17 diff_order=1,
18 scaler='z-norm' # Apply scaling at the end
19)
20
21print("--- Engineered Features ---")
22print("Columns:", df_featured.columns.tolist())
23print("\nHead (Note NaNs from lags/rolling/diff & scaling):")
24print(df_featured.head())
create_lag_features¶
- API Reference:
Purpose: To generate lagged features for one or more specified time series columns in a DataFrame. Lag features represent past values and are fundamental predictors for many time series models.
Functionality:
Takes df, value_col, optional dt_col, optional list lag_features, and list of integer lags.
Ensures datetime index (using ts_validator).
For each specified feature and lag interval \(k\) in lags, creates a new column
<feature>_lag_<k>by shifting the original column down by \(k\) steps.\[\text{Feature}_{lag\_k}(t) = \text{Feature}(t-k)\]Optionally includes original columns (include_original).
Optionally drops rows with NaNs created by shifting (dropna).
Optionally resets the index (reset_index).
Usage Context: A core feature engineering step. Use this function
when you specifically need to create lag features for one or more columns.
For a broader range of features (rolling stats, time features, etc.),
consider ts_engineering().
Code Example:
1import pandas as pd
2import numpy as np
3from fusionlab.utils.ts_utils import create_lag_features
4
5# Create dummy data
6dates = pd.date_range('2023-01-01', periods=10)
7df = pd.DataFrame({
8 'Date': dates,
9 'Value': np.arange(10) + 5,
10 'Other': np.arange(10) * 2 + 3
11})
12df = df.set_index('Date')
13
14# Create lags 1 and 2 for 'Value' column
15df_lagged = create_lag_features(
16 df.copy(),
17 value_col='Value',
18 lags=[1, 2],
19 dropna=False, # Keep NaNs initially
20 include_original=True,
21 reset_index=False # Keep datetime index
22)
23
24print("--- DataFrame with Lag Features ---")
25print(df_lagged.head())
26
27# Example dropping NaNs
28df_lagged_dropped = create_lag_features(
29 df.copy(), value_col='Value', lags=[1, 2], dropna=True
30)
31print("\n--- DataFrame with Lags (NaNs Dropped) ---")
32print(df_lagged_dropped.head())
Feature Selection & Reduction¶
After potentially generating many features (e.g., via lags, rolling stats, etc.), these utilities can help select the most relevant ones or reduce the dimensionality of the feature space.
select_and_reduce_features¶
- API Reference:
Purpose: To perform feature selection by removing highly correlated features or reduce dimensionality using Principal Component Analysis (PCA).
Functionality: Takes df, optional target_col/exclude_cols. Operates based on method:
method=’corr’: Removes features highly correlated with others.
Calculates pairwise Pearson correlation matrix for numeric features.
Identifies pairs exceeding corr_threshold.
Drops one feature from each highly correlated pair.
method=’pca’: Uses Principal Component Analysis.
Optionally standardizes features (scale_data=True). Requires scikit-learn.
Applies sklearn.decomposition.PCA to keep n_components (either an int count or a float variance ratio).
Replaces original features with principal components (PCs).
\[\text{ExplainedVarianceRatio}(PC_i) = \frac{\lambda_i}{\sum_j \lambda_j}\]where \(\lambda_i\) are eigenvalues.
Returns transformed DataFrame (optionally with target). Can also return the fitted PCA model (return_pca=True).
Usage Context: Use after extensive feature engineering (ts_engineering())
to combat multicollinearity (method=’corr’) or reduce feature dimensions
(method=’pca’) before model training. Requires scikit-learn for PCA.
Code Examples:
Example 1: Correlation-Based Selection
1import pandas as pd
2import numpy as np
3from fusionlab.utils.ts_utils import select_and_reduce_features
4
5# Dummy data with correlated features
6data = {
7 'A': np.arange(10),
8 'B': np.arange(10) * 1.05 + np.random.randn(10)*0.1, # Highly correlated with A
9 'C': np.random.randn(10), # Uncorrelated
10 'Target': np.random.randint(0, 2, 10)
11}
12df = pd.DataFrame(data)
13print("--- Original Columns ---")
14print(df.columns.tolist())
15
16# Select features, removing those with >0.95 correlation
17df_selected = select_and_reduce_features(
18 df.copy(),
19 target_col='Target',
20 method='corr',
21 corr_threshold=0.95
22)
23print("\n--- Columns after Correlation Selection ---")
24print(df_selected.columns.tolist()) # Should drop 'B'
Example 2: PCA Reduction
1import pandas as pd
2import numpy as np
3# Assuming select_and_reduce_features is importable
4from fusionlab.utils.ts_utils import select_and_reduce_features
5
6# Use same dummy data
7data = {
8 'A': np.arange(10), 'B': np.arange(10) * 1.05,
9 'C': np.random.randn(10), 'Target': np.random.randint(0, 2, 10)
10}
11df = pd.DataFrame(data)
12
13# Reduce features A, B, C to 2 principal components
14df_pca, pca_model = select_and_reduce_features(
15 df.copy(),
16 target_col='Target',
17 method='pca',
18 n_components=2, # Keep top 2 components
19 scale_data=True, # Recommended for PCA
20 return_pca=True
21)
22print("\n--- DataFrame after PCA Reduction ---")
23print(df_pca.head())
24print("\nExplained Variance Ratio per component:")
25print(pca_model.explained_variance_ratio_)