Exercise: Anomaly Detection¶
Welcome to this exercise on anomaly detection using fusionlab-learn!
In this guide, you’ll walk through practical examples of using the
specialized anomaly detection components available in the
fusionlab.nn.anomaly_detection module. These components can
help you build models to identify unusual patterns in your time series
data.
Learning Objectives:
Understand and implement an LSTM Autoencoder for reconstruction-based anomaly detection.
Learn the conceptual use of the SequenceAnomalyScoreLayer for feature-based scoring within larger models.
Apply the PredictionErrorAnomalyScore layer to derive anomaly scores from model prediction errors.
Let’s get started!
Prerequisites¶
Before you begin, ensure you have fusionlab-learn and its
common dependencies installed. For visualizations, matplotlib is
also needed.
pip install fusionlab-learn matplotlib scikit-learn
Exercise 1: Unsupervised Anomaly Detection with LSTM Autoencoder¶
In this first exercise, we’ll build and train an LSTM Autoencoder. The core idea is that an autoencoder trained on “normal” data will struggle to reconstruct anomalous data points or sequences, leading to higher reconstruction errors for those anomalies.
Workflow:
Generate synthetic time series data with some manually injected anomalies.
Preprocess the data: scale it and create input sequences.
Define, compile, and train the
LSTMAutoencoderAnomalymodel.Use the trained model to reconstruct the sequences and calculate reconstruction errors.
Identify anomalies by setting a threshold on these errors.
Visualize the original data, detected anomalies, and the error scores.
- Step 1.1: Imports and Setup
First, let’s import all the necessary libraries.
1import numpy as np
2import pandas as pd
3import tensorflow as tf
4import matplotlib.pyplot as plt
5from sklearn.preprocessing import StandardScaler
6import warnings
7import os
8
9# FusionLab imports
10from fusionlab.nn.anomaly_detection import LSTMAutoencoderAnomaly
11from fusionlab.nn.utils import create_sequences # For sequence prep
12
13# Suppress warnings and TF logs for cleaner output
14warnings.filterwarnings('ignore')
15tf.get_logger().setLevel('ERROR')
16if hasattr(tf, 'autograph'): # Check for autograph availability
17 tf.autograph.set_verbosity(0)
18
19# Directory for saving any output images from this exercise
20exercise_output_dir = "./anomaly_detection_exercise_outputs"
21os.makedirs(exercise_output_dir, exist_ok=True)
22
23print("Libraries imported for LSTM Autoencoder exercise.")
- Step 1.2: Generate Synthetic Data with Anomalies
We’ll create a simple sine wave and add some obvious anomalies to it.
1np.random.seed(42) # For reproducibility
2time_points = np.arange(0, 200, 0.5)
3# Base normal signal
4normal_signal = np.sin(time_points * 0.5) + \
5 np.random.normal(0, 0.1, len(time_points))
6# Inject some anomalies
7data_with_anomalies = normal_signal.copy()
8data_with_anomalies[50:60] += 2.0 # A positive spike/shift
9data_with_anomalies[150:155] -= 1.5 # A negative dip/shift
10
11df_exercise = pd.DataFrame({
12 'Time': time_points,
13 'Value': data_with_anomalies
14 })
15print("Generated data shape for exercise:", df_exercise.shape)
16
17# Let's visualize our data
18plt.figure(figsize=(12, 3))
19plt.plot(df_exercise['Time'], df_exercise['Value'],
20 label='Data with Injected Anomalies')
21plt.title("Synthetic Time Series for Anomaly Detection Exercise")
22plt.xlabel("Time Index")
23plt.ylabel("Value")
24plt.legend()
25plt.grid(True)
26# To save for documentation:
27# plt.savefig(os.path.join(
28# exercise_output_dir, "exercise_ad_synthetic_data.png"))
29plt.show()
Expected Plot 1.2:
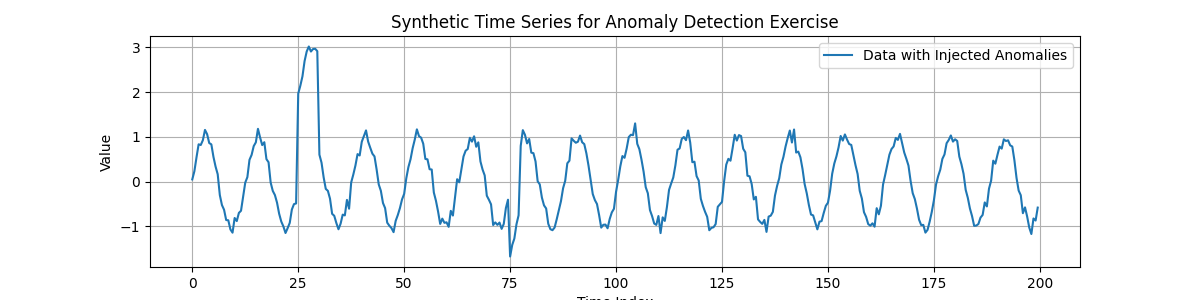
Synthetic time series with manually injected anomalous periods.¶
- Step 1.3: Preprocessing - Scaling and Sequence Creation
Neural networks generally perform better with scaled data. We’ll use StandardScaler. Then, we’ll create overlapping sequences from our time series, as LSTMs operate on sequences. For an autoencoder, the input sequence is also its own target for reconstruction.
1scaler_ad_ex = StandardScaler()
2df_exercise['Value_Scaled'] = scaler_ad_ex.fit_transform(
3 df_exercise[['Value']]
4 )
5print("\nData scaled using StandardScaler.")
6
7sequence_len_ex = 20 # Length of sequences for the autoencoder
8
9# Using create_sequences: target_col is 'Value_Scaled',
10# forecast_horizon=0 means reconstruct the input sequence itself.
11sequences_ex, _ = create_sequences(
12 df_exercise[['Value_Scaled']],
13 sequence_length=sequence_len_ex,
14 target_col='Value_Scaled',
15 forecast_horizon=0, # Reconstruct the input sequence
16 drop_last=False, # Keep all possible sequences
17 verbose=0
18)
19# For autoencoder, input (X) and target (y) are the same
20X_train_ae = sequences_ex.reshape(
21 sequences_ex.shape[0], sequence_len_ex, 1 # Features=1
22 ).astype(np.float32)
23y_train_ae = X_train_ae.copy() # Target is the input itself
24
25print(f"Created sequences for autoencoder. X_train shape: "
26 f"{X_train_ae.shape}")
Expected Output 1.3:
Data scaled using StandardScaler.
Created sequences for autoencoder. X_train shape: (381, 20, 1)
- Step 1.4: Define LSTM Autoencoder Model
Now, we instantiate our
LSTMAutoencoderAnomaly. Key parameters are latent_dim (size of the compressed representation) and lstm_units. n_features should match our input, and n_repeats should match sequence_len_ex for reconstruction.
1latent_dim_ae = 8
2lstm_units_ae = 16 # Units in LSTM layers
3
4lstm_ae_model_ex = LSTMAutoencoderAnomaly(
5 latent_dim=latent_dim_ae,
6 lstm_units=lstm_units_ae,
7 n_features=X_train_ae.shape[-1], # Should be 1
8 n_repeats=sequence_len_ex, # Output sequence length
9 num_encoder_layers=1,
10 num_decoder_layers=1,
11 activation='linear' # Good for reconstructing potentially unbounded scaled data
12)
13print("\nLSTM Autoencoder model defined.")
- Step 1.5: Compile and Train the Autoencoder
We compile with ‘adam’ optimizer and ‘mse’ loss, then train the model. The model learns to reconstruct the input sequences.
1lstm_ae_model_ex.compile(optimizer='adam', loss='mse')
2print("Autoencoder compiled. Starting training...")
3
4# Build the model with input shape before fitting
5lstm_ae_model_ex.build(input_shape=(None, sequence_len_ex, X_train_ae.shape[-1]))
6# lstm_ae_model_ex.summary() # Optional: view model structure
7
8history_ae = lstm_ae_model_ex.fit(
9 X_train_ae, y_train_ae, # Input and target are the same
10 epochs=20, # Train for more epochs for better learning
11 batch_size=16,
12 shuffle=True, # Shuffle sequences during training
13 verbose=0 # Suppress Keras fit logs for this example
14)
15print("Training finished.")
16if history_ae and history_ae.history.get('loss'):
17 print(f"Final training loss (MSE): {history_ae.history['loss'][-1]:.4f}")
- Expected Output 1.5:
(The loss value will vary slightly due to random initialization)
Autoencoder compiled. Starting training...
Training finished.
Final training loss (MSE): 0.0617
- Step 1.6: Calculate Reconstruction Errors (Anomaly Scores)
After training, we use the model to reconstruct all sequences and calculate the Mean Squared Error (MSE) for each. This MSE serves as our anomaly score for each sequence window.
1print("\nCalculating reconstruction errors...")
2reconstruction_errors_ex = lstm_ae_model_ex.compute_reconstruction_error(
3 X_train_ae # Pass all sequences to get their errors
4).numpy() # Get as NumPy array
5print(f"Reconstruction errors shape: {reconstruction_errors_ex.shape}")
6
7# Map sequence errors back to original time points for plotting
8# (Assign error of a sequence to its last point for simplicity)
9errors_mapped_ex = np.full(len(df_exercise), np.nan)
10for i in range(len(reconstruction_errors_ex)):
11 # Ensure index is within bounds
12 end_point_idx = i + sequence_len_ex - 1
13 if end_point_idx < len(errors_mapped_ex):
14 errors_mapped_ex[end_point_idx] = reconstruction_errors_ex[i]
15
16df_exercise['ReconstructionError'] = errors_mapped_ex
Expected Output 1.6:
Calculating reconstruction errors...
Reconstruction errors shape: (381,)
- Step 1.7: Detect Anomalies using a Threshold
We define a threshold based on the distribution of reconstruction errors (e.g., the 95th percentile). Sequences with errors above this threshold are flagged as anomalies.
1# Define threshold (e.g., based on error distribution percentile)
2# Ensure to use only non-NaN errors for percentile calculation
3valid_errors_ex = df_exercise['ReconstructionError'].dropna()
4if not valid_errors_ex.empty:
5 threshold_ex = np.percentile(valid_errors_ex, 95)
6 df_exercise['Is_Anomaly'] = df_exercise['ReconstructionError'] > threshold_ex
7 print(f"\nAnomaly threshold (95th percentile error): {threshold_ex:.4f}")
8 print(f"Number of points flagged as anomalies: {df_exercise['Is_Anomaly'].sum()}")
9else:
10 print("\nNo valid reconstruction errors to calculate threshold.")
11 df_exercise['Is_Anomaly'] = False # Default if no errors
- Expected Output 1.7:
(Values will vary)
Anomaly threshold (95th percentile error): 0.3643
Number of points flagged as anomalies: 19
- Step 1.8: Visualize Results
Finally, plot the original data with detected anomalies and the reconstruction error over time.
1fig_ae, ax_ae = plt.subplots(2, 1, figsize=(14, 8), sharex=True)
2
3ax_ae[0].plot(df_exercise['Time'], df_exercise['Value'],
4 label='Original Data', zorder=1)
5anomalies_ex = df_exercise[df_exercise['Is_Anomaly']]
6if not anomalies_ex.empty:
7 ax_ae[0].scatter(anomalies_ex['Time'], anomalies_ex['Value'],
8 color='red', label='Detected Anomaly',
9 zorder=5, s=50)
10ax_ae[0].set_ylabel('Value')
11ax_ae[0].set_title('Time Series with Detected Anomalies (LSTM Autoencoder)')
12ax_ae[0].legend(); ax_ae[0].grid(True)
13
14ax_ae[1].plot(df_exercise['Time'], df_exercise['ReconstructionError'],
15 label='Reconstruction Error (MSE per Sequence)',
16 color='orange')
17if 'threshold_ex' in locals() and np.isfinite(threshold_ex):
18 ax_ae[1].axhline(threshold_ex, color='red', linestyle='--',
19 label=f'Threshold ({threshold_ex:.2f})')
20ax_ae[1].set_ylabel('Reconstruction Error (MSE)')
21ax_ae[1].set_xlabel('Time')
22ax_ae[1].set_title('Reconstruction Error and Anomaly Threshold')
23ax_ae[1].legend(); ax_ae[1].grid(True)
24
25plt.tight_layout()
26# To save for documentation:
27# plt.savefig(os.path.join(
28# exercise_output_dir, "exercise_ad_lstm_ae_results.png"))
29plt.show()
Expected Plot 1.8:

Top: Original signal with detected anomalies highlighted. Bottom: Reconstruction error over time with the anomaly threshold.¶
- Discussion of Exercise 1:
The LSTM Autoencoder learns the “normal” patterns in the time series. When it encounters sequences that are significantly different (our injected anomalies), it cannot reconstruct them well, leading to a spike in the reconstruction error. By setting a threshold on this error, we can flag these anomalous periods. The choice of sequence_length, latent_dim, lstm_units, and the error threshold are important hyperparameters that would typically be tuned.
Exercise 2: Using SequenceAnomalyScoreLayer (Conceptual)¶
The SequenceAnomalyScoreLayer
is a component, not a standalone model. It’s designed to be part of a
larger neural network (like XTFT). It takes learned features from
preceding layers and passes them through a small Multi-Layer
Perceptron (MLP) to output a single anomaly score per input sample.
Concept: Imagine you have a model that processes time series and extracts meaningful features (e.g., the output of an LSTM encoder or an attention mechanism). You can then feed these features into the SequenceAnomalyScoreLayer to get an anomaly score. This score can then be used in a custom loss function to train the entire model in an anomaly-aware manner.
- Step 2.1: Imports and Setup
We only need TensorFlow and the layer itself.
1import tensorflow as tf
2from fusionlab.nn.anomaly_detection import SequenceAnomalyScoreLayer
3print("\nLibraries imported for SequenceAnomalyScoreLayer exercise.")
- Step 2.2: Instantiate and Use the Layer
Let’s simulate some “learned features” and see how the layer processes them.
1# Assume 'learned_features_ex2' is the output of a preceding layer
2# Shape: (Batch, FeatureDim)
3batch_size_ex2 = 16
4feature_dim_ex2 = 64 # Example dimension of learned features
5learned_features_ex2 = tf.random.normal(
6 (batch_size_ex2, feature_dim_ex2), dtype=tf.float32
7 )
8
9# Instantiate the scoring layer
10anomaly_scorer_ex2 = SequenceAnomalyScoreLayer(
11 hidden_units=[32, 16], # Define MLP structure within the layer
12 activation='relu',
13 dropout_rate=0.1,
14 final_activation='linear' # Output an unbounded score
15)
16
17# Pass features through the layer to get scores
18# In a real model, this happens within its 'call' method.
19anomaly_scores_ex2 = anomaly_scorer_ex2(
20 learned_features_ex2, training=False # Set training appropriately
21 )
22
23print(f"\nInput features shape for scorer: {learned_features_ex2.shape}")
24print(f"Output anomaly scores shape: {anomaly_scores_ex2.shape}")
25print("Sample scores:", anomaly_scores_ex2.numpy()[:5].flatten())
Expected Output 2.2:
Input features shape for scorer: (16, 64)
Output anomaly scores shape: (16, 1)
Sample scores: [ 0.19996917 -0.8162031 0.6714213 -0.36490577 1.3606443 ]
- Discussion of Exercise 2:
This layer provides a trainable mechanism to derive anomaly scores from abstract feature representations. To make it useful, it needs to be part of an end-to-end model trained with a loss function that relates these scores to actual anomalies or desired behavior (e.g., penalizing high scores for normal data if labels are available, or using it in an unsupervised reconstruction + anomaly score setup). Refer to the XTFT ‘feature_based’ strategy in the User Guide for more on integration.
Exercise 3: Using PredictionErrorAnomalyScore¶
The PredictionErrorAnomalyScore
layer directly calculates an anomaly score based on the discrepancy
(error) between true values (y_true) and a model’s predicted values
(y_pred) for a sequence.
Concept: If a forecasting model makes large errors for a particular sequence, that sequence might be anomalous or represent a regime the model hasn’t learned well. This layer quantifies that prediction error.
- Step 3.1: Imports and Setup
We need TensorFlow and the layer.
1import tensorflow as tf
2import numpy as np # For a more visible error injection
3from fusionlab.nn.anomaly_detection import PredictionErrorAnomalyScore
4print("\nLibraries imported for PredictionErrorAnomalyScore exercise.")
- Step 3.2: Instantiate and Use the Layer
We’ll create dummy y_true and y_pred tensors, then see how the layer calculates scores.
1# Configuration for dummy data
2batch_size_ex3 = 4
3time_steps_ex3 = 10
4features_ex3 = 1 # Univariate example
5
6# Dummy true values
7y_true_ex3 = tf.random.normal(
8 (batch_size_ex3, time_steps_ex3, features_ex3), dtype=tf.float32
9 )
10# Dummy predicted values with some errors
11y_pred_ex3_np = y_true_ex3.numpy() + np.random.normal(
12 scale=0.5, size=y_true_ex3.shape
13 ).astype(np.float32)
14# Inject a larger error into one sample's prediction
15y_pred_ex3_np[1, 3, 0] += 4.0 # Large error for sample 1, time step 3
16y_pred_ex3 = tf.constant(y_pred_ex3_np)
17
18# --- Instantiate with MAE and Mean Aggregation ---
19error_scorer_mean_ex3 = PredictionErrorAnomalyScore(
20 error_metric='mae', # Use Mean Absolute Error
21 aggregation='mean' # Average errors across time steps
22)
23anomaly_scores_mean_ex3 = error_scorer_mean_ex3([y_true_ex3, y_pred_ex3])
24
25# --- Instantiate with MAE and Max Aggregation ---
26error_scorer_max_ex3 = PredictionErrorAnomalyScore(
27 error_metric='mae',
28 aggregation='max' # Take max error across time steps
29)
30anomaly_scores_max_ex3 = error_scorer_max_ex3([y_true_ex3, y_pred_ex3])
31
32print(f"\nInput y_true shape: {y_true_ex3.shape}")
33print(f"Input y_pred shape: {y_pred_ex3.shape}")
34print("\n--- MAE + Mean Aggregation ---")
35print(f"Output anomaly scores shape: {anomaly_scores_mean_ex3.shape}")
36print(f"Example Scores (Mean Error per sequence): \n"
37 f"{anomaly_scores_mean_ex3.numpy().flatten()}")
38print("\n--- MAE + Max Aggregation ---")
39print(f"Output anomaly scores shape: {anomaly_scores_max_ex3.shape}")
40print(f"Example Scores (Max Error per sequence): \n"
41 f"{anomaly_scores_max_ex3.numpy().flatten()}")
- Expected Output 3.2:
(Error values will vary. Note how the score for the second sequence (index 1) is likely higher with ‘max’ aggregation due to the injected large error.)
Input y_true shape: (4, 10, 1)
Input y_pred shape: (4, 10, 1)
--- MAE + Mean Aggregation ---
Output anomaly scores shape: (4, 1)
Example Scores (Mean Error per sequence):
[0.25818387 0.83212453 0.5759385 0.52767694]
--- MAE + Max Aggregation ---
Output anomaly scores shape: (4, 1)
Example Scores (Max Error per sequence):
[0.7972139 4.6388383 1.0303739 1.0196161]
- Discussion of Exercise 3:
The PredictionErrorAnomalyScore layer provides a straightforward way to quantify how “surprising” a sequence is to a pre-trained forecasting model. These scores can be directly used in a loss function to penalize the main forecasting model when it makes large errors, effectively making it anomaly-aware. This aligns with the ‘prediction_based’ anomaly detection strategy in
XTFT.