XTFT Forecasting with Anomaly Detection¶
This example demonstrates how to leverage the anomaly detection
features integrated within the XTFT model.
Incorporating anomaly information during training can potentially
make the model more robust to irregularities and improve forecasting
performance, especially on noisy real-world data.
We will adapt the setup from the Advanced Forecasting with XTFT example and show two main approaches for integrating anomaly detection into a multi-step quantile forecasting task:
Strategy 1: Using Pre-computed Anomaly Scores: We’ll first calculate anomaly scores externally (e.g., using
compute_anomaly_scores()) and then incorporate them into the training loss using a combined loss function (combined_total_loss()).Strategy 2: Using Prediction-Based Errors: We’ll configure XTFT to use the
anomaly_detection_strategy = 'prediction_based', where the anomaly signal is derived directly from prediction errors during training via a specialized loss function (prediction_based_loss()).
Prerequisites¶
Ensure you have fusionlab-learn and its dependencies installed:
pip install fusionlab-learn matplotlib scikit-learn joblib
Strategy 1: Using Pre-computed Anomaly Scores¶
In this strategy, we assume we have a way to generate anomaly scores for our target variable before training the main forecasting model. These scores are then used to create a combined loss function.
Step 1.1: Imports and Setup¶
Import standard libraries and fusionlab components.
1import numpy as np
2import pandas as pd
3import tensorflow as tf
4import matplotlib.pyplot as plt
5from sklearn.model_selection import train_test_split
6from sklearn.preprocessing import StandardScaler
7import os
8import joblib
9
10# FusionLab imports
11from fusionlab.nn.transformers import XTFT
12from fusionlab.nn.utils import (
13 reshape_xtft_data,
14 compute_anomaly_scores # For pre-calculating scores
15)
16from fusionlab.nn.losses import (
17 combined_quantile_loss,
18 combined_total_loss, # For Strategy 1
19 prediction_based_loss # For Strategy 2
20)
21from fusionlab.nn.components import AnomalyLoss # For combined_total_loss
22
23# Suppress warnings and TF logs
24import warnings
25warnings.filterwarnings('ignore')
26tf.get_logger().setLevel('ERROR')
27if hasattr(tf, 'autograph'):
28 tf.autograph.set_verbosity(0)
29
30output_dir_xtft_anom = "./xtft_anomaly_example_output"
31os.makedirs(output_dir_xtft_anom, exist_ok=True)
32print("Libraries imported for XTFT Anomaly Detection Example.")
Step 1.2: Generate Synthetic Data (with Anomalies)¶
We create multi-item time series data, similar to the advanced XTFT example, but intentionally inject some anomalies (spikes/dips) into the ‘Sales’ target variable for one of the items.
1n_items = 3
2n_timesteps = 48 # More data for anomaly context
3rng_seed = 123
4np.random.seed(rng_seed)
5
6date_rng = pd.date_range(
7 start='2019-01-01', periods=n_timesteps, freq='MS')
8df_list = []
9
10for item_id in range(n_items):
11 time_idx = np.arange(n_timesteps)
12 sales = (
13 100 + item_id * 30 + time_idx * (1.5 + item_id * 0.3) +
14 25 * np.sin(2 * np.pi * time_idx / 12) + # Yearly seasonality
15 np.random.normal(0, 8, n_timesteps) # Base noise
16 )
17 # Inject anomalies for item_id 1
18 if item_id == 1:
19 sales[10] = sales[10] + 80 # Positive spike
20 sales[25] = sales[25] - 60 # Negative dip
21 print(f"Injected anomalies for ItemID {item_id} at indices 10 and 25.")
22
23 temp = (15 + 10 * np.sin(2 * np.pi * (time_idx % 12) / 12 + np.pi) +
24 np.random.normal(0, 1.5, n_timesteps))
25 promo = np.random.randint(0, 2, n_timesteps)
26
27 item_df = pd.DataFrame({
28 'Date': date_rng, 'ItemID': f'item_{item_id}',
29 'Month': date_rng.month, 'Temperature': temp,
30 'PlannedPromotion': promo, 'Sales': sales
31 })
32 item_df['PrevMonthSales'] = item_df['Sales'].shift(1)
33 df_list.append(item_df)
34
35df_raw_anom = pd.concat(df_list).dropna().reset_index(drop=True)
36print(f"\nGenerated data with anomalies, shape: {df_raw_anom.shape}")
Step 1.3: Define Features & Scale¶
Define column roles and scale the numerical features.
1target_col_anom = 'Sales'
2dt_col_anom = 'Date'
3static_cols_anom = ['ItemID']
4dynamic_cols_anom = ['Month', 'Temperature', 'PrevMonthSales']
5future_cols_anom = ['PlannedPromotion', 'Month']
6spatial_cols_anom = ['ItemID'] # For grouping
7scalers_anom = {}
8num_cols_to_scale_anom = ['Temperature', 'PrevMonthSales', 'Sales']
9df_scaled_anom = df_raw_anom.copy()
10
11for col in num_cols_to_scale_anom:
12 if col in df_scaled_anom.columns:
13 scaler = StandardScaler()
14 df_scaled_anom[col] = scaler.fit_transform(df_scaled_anom[[col]])
15 scalers_anom[col] = scaler
16 print(f"Scaled column: {col}")
17
18scalers_path_anom = os.path.join(output_dir_xtft_anom, "xtft_anom_scalers.joblib")
19joblib.dump(scalers_anom, scalers_path_anom)
20print(f"Scalers saved to {scalers_path_anom}")
Step 1.4: Prepare Sequences¶
Use reshape_xtft_data to create sequence arrays.
1time_steps_anom = 12
2forecast_horizons_anom = 6
3static_cols_for_reshape = [] # No additional static features here
4
5s_data, d_data, f_data, t_data = reshape_xtft_data(
6 df=df_scaled_anom, dt_col=dt_col_anom, target_col=target_col_anom,
7 dynamic_cols=dynamic_cols_anom, static_cols=static_cols_for_reshape,
8 future_cols=future_cols_anom, spatial_cols=spatial_cols_anom,
9 time_steps=time_steps_anom, forecast_horizons=forecast_horizons_anom,
10 verbose=0
11)
12print(f"\nSequence shapes: S={s_data.shape if s_data is not None else 'None'}, "
13 f"D={d_data.shape}, F={f_data.shape}, T={t_data.shape}")
Step 1.5: Pre-compute Anomaly Scores¶
Calculate anomaly scores for the target sequences.
1print("\nCalculating anomaly scores for target sequences...")
2anomaly_scores_all_seq = compute_anomaly_scores(
3 y_true=t_data, method='statistical', verbose=0
4)
5print(f"Computed anomaly scores shape: {anomaly_scores_all_seq.shape}")
Step 1.6: Train/Validation Split (Including Anomaly Scores)¶
Split all arrays: static, dynamic, future, target, and anomaly scores.
1val_split_frac_anom = 0.2
2n_seq_anom = t_data.shape[0]
3split_idx_anom = int(n_seq_anom * (1 - val_split_frac_anom))
4
5X_s_train, X_s_val = (s_data[:split_idx_anom], s_data[split_idx_anom:]) \
6 if s_data is not None else (None, None)
7X_d_train, X_d_val = d_data[:split_idx_anom], d_data[split_idx_anom:]
8X_f_train, X_f_val = f_data[:split_idx_anom], f_data[split_idx_anom:]
9y_train, y_val = t_data[:split_idx_anom], t_data[split_idx_anom:]
10
11anomaly_scores_train = anomaly_scores_all_seq[:split_idx_anom]
12anomaly_scores_val = anomaly_scores_all_seq[split_idx_anom:]
13
14train_inputs = [X_s_train, X_d_train, X_f_train]
15val_inputs = [X_s_val, X_d_val, X_f_val]
16print("\nData (including anomaly scores) split into Train/Validation.")
Step 1.7: Define XTFT Model and Combined Loss (Strategy 1)¶
Instantiate XTFT. Use combined_total_loss with an AnomalyLoss component and the pre-computed anomaly_scores_train.
1quantiles_anom = [0.1, 0.5, 0.9]
2anomaly_loss_weight_s1 = 0.1 # Weight for Strategy 1
3
4s_dim_anom = X_s_train.shape[-1] if X_s_train is not None else 0
5d_dim_anom = X_d_train.shape[-1]
6f_dim_anom = X_f_train.shape[-1] if X_f_train is not None else 0
7
8model_s1 = XTFT(
9 static_input_dim=s_dim_anom, dynamic_input_dim=d_dim_anom,
10 future_input_dim=f_dim_anom,
11 forecast_horizon=forecast_horizons_anom,
12 quantiles=quantiles_anom, output_dim=1,
13 hidden_units=16, embed_dim=8, num_heads=2,
14 lstm_units=16, attention_units=16, max_window_size=time_steps_anom,
15 anomaly_loss_weight=anomaly_loss_weight_s1 # Passed to AnomalyLoss
16)
17
18anomaly_loss_component_s1 = AnomalyLoss(weight=anomaly_loss_weight_s1)
19loss_s1 = combined_total_loss(
20 quantiles=quantiles_anom,
21 anomaly_layer=anomaly_loss_component_s1,
22 anomaly_scores=tf.constant(anomaly_scores_train, dtype=tf.float32)
23)
24model_s1.compile(
25 optimizer=tf.keras.optimizers.Adam(learning_rate=0.005),
26 loss=loss_s1
27)
28print("\nXTFT (Strategy 1) compiled with combined loss.")
Step 1.8: Train Model (Strategy 1)¶
Train the model.
1print("Starting XTFT training (Strategy 1: Pre-computed Scores)...")
2history_s1 = model_s1.fit(
3 train_inputs, y_train,
4 validation_data=(val_inputs, y_val),
5 epochs=5, batch_size=16, verbose=1
6)
7print("Training (Strategy 1) finished.")
8if history_s1 and history_s1.history.get('val_loss'):
9 print(f"S1 - Final validation loss: {history_s1.history['val_loss'][-1]:.4f}")
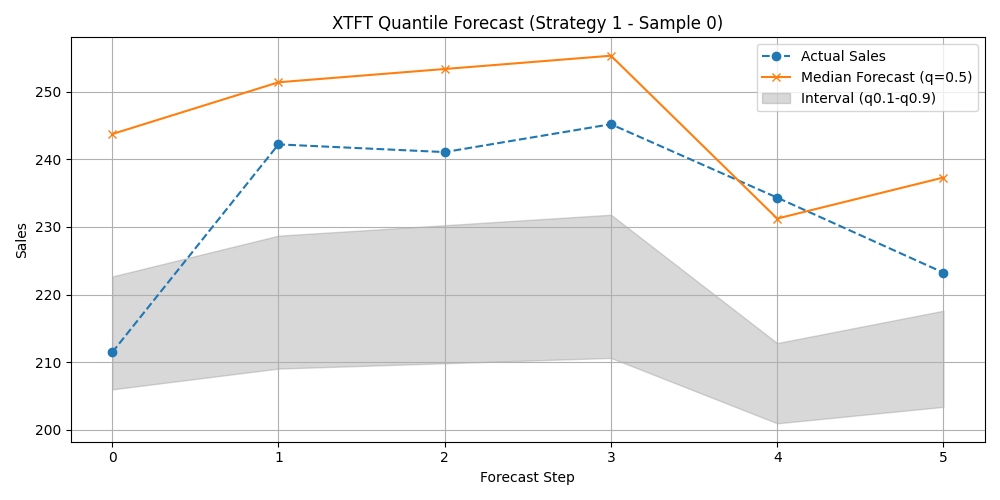
Step 1.9: Prediction & Visualization (Strategy 1)¶
Prediction and visualization are standard.
1print("\nMaking predictions with Strategy 1 model...")
2predictions_scaled_s1 = model_s1.predict(val_inputs, verbose=0)
3
4# Inverse Transform
5target_scaler_s1 = scalers_anom.get(target_col_anom)
6if target_scaler_s1:
7 num_val_s1 = val_inputs[0].shape[0] if val_inputs[0] is not None else val_inputs[1].shape[0]
8 num_q_s1 = len(quantiles_anom)
9 output_dim_s1 = 1 # Assuming univariate target
10
11 pred_reshaped_s1 = predictions_scaled_s1.reshape(-1, num_q_s1 * output_dim_s1)
12 predictions_inv_s1 = target_scaler_s1.inverse_transform(pred_reshaped_s1)
13 predictions_final_s1 = predictions_inv_s1.reshape(
14 num_val_s1, forecast_horizons_anom, num_q_s1
15 )
16 y_val_reshaped_s1 = y_val.reshape(-1, output_dim_s1)
17 y_val_inv_s1 = target_scaler_s1.inverse_transform(y_val_reshaped_s1)
18 y_val_final_s1 = y_val_inv_s1.reshape(
19 num_val_s1, forecast_horizons_anom, output_dim_s1
20 )
21 print("Predictions and actuals inverse transformed for Strategy 1.")
22else:
23 print("Warning: Target scaler not found for Strategy 1. Plotting scaled values.")
24 predictions_final_s1 = predictions_scaled_s1
25 y_val_final_s1 = y_val
26
27# Visualize for one sample
28sample_to_plot_s1 = 0
29actual_vals_s1 = y_val_final_s1[sample_to_plot_s1, :, 0]
30pred_quantiles_s1 = predictions_final_s1[sample_to_plot_s1, :, :]
31time_axis_s1 = np.arange(forecast_horizons_anom)
32
33plt.figure(figsize=(10, 5))
34plt.plot(time_axis_s1, actual_vals_s1, label='Actual Sales', marker='o', linestyle='--')
35plt.plot(time_axis_s1, pred_quantiles_s1[:, 1], label='Median Forecast (q=0.5)', marker='x')
36plt.fill_between(
37 time_axis_s1, pred_quantiles_s1[:, 0], pred_quantiles_s1[:, 2],
38 color='gray', alpha=0.3, label='Interval (q0.1-q0.9)'
39)
40plt.title(f'XTFT Quantile Forecast (Strategy 1 - Sample {sample_to_plot_s1})')
41plt.xlabel('Forecast Step'); plt.ylabel('Sales')
42plt.legend(); plt.grid(True); plt.tight_layout()
43# plt.savefig(os.path.join(output_dir_xtft_anom, "s1_forecast_plot.png"))
44plt.show()
45print("Strategy 1: Plot generated.")
46
47# [out] Training (Strategy 1) finished.
48# S1 - Final validation loss: 0.4350
Example Output Plot:
Strategy 2: Using Prediction-Based Errors¶
This approach configures XTFT to derive anomaly signals directly from its own prediction errors during training.
(Data from Steps 1.2 (df_raw_anom), 1.3 (df_scaled_anom, scalers_anom), 1.4 (s_data, d_data, f_data, t_data), and 1.6 (train_inputs, val_inputs, y_train, y_val) are assumed to be available here. We do not use the pre-computed `anomaly_scores_all_seq` for this strategy.)
Step 2.1: Define XTFT Model (Prediction-Based)¶
Instantiate XTFT with anomaly_detection_strategy=’prediction_based’ and provide anomaly_loss_weight.
1print("\n--- Configuring for Strategy 2: 'prediction_based' ---")
2anomaly_weight_s2 = 0.05 # Weight for prediction error penalty
3
4# Re-use dimensions from Strategy 1 data prep for consistency
5s_dim_s2 = X_s_train.shape[-1] if X_s_train is not None else 0
6
7model_s2 = XTFT(
8 static_input_dim=s_dim_s2,
9 dynamic_input_dim=X_d_train.shape[-1],
10 future_input_dim=X_f_train.shape[-1] if X_f_train is not None else 0,
11 forecast_horizon=forecast_horizons_anom,
12 quantiles=quantiles_anom, output_dim=1,
13 hidden_units=16, embed_dim=8, num_heads=2,
14 lstm_units=16, attention_units=16, max_window_size=time_steps_anom,
15 anomaly_detection_strategy='prediction_based',
16 anomaly_loss_weight=anomaly_weight_s2
17)
18print("XTFT (Strategy 2) instantiated with 'prediction_based'.")
Step 2.2: Compile with Prediction-Based Loss¶
Use the prediction_based_loss() factory.
1loss_s2 = prediction_based_loss(
2 quantiles=quantiles_anom,
3 anomaly_loss_weight=anomaly_weight_s2
4)
5model_s2.compile(
6 optimizer=tf.keras.optimizers.Adam(learning_rate=0.005),
7 loss=loss_s2
8)
9print("XTFT (Strategy 2) compiled with prediction_based_loss.")
Step 2.3: Train Model (Strategy 2)¶
Train the model. The combined loss is handled internally.
1print("\nStarting XTFT training (Strategy 2: Prediction-Based)...")
2history_s2 = model_s2.fit(
3 train_inputs, y_train,
4 validation_data=(val_inputs, y_val),
5 epochs=5, batch_size=16, verbose=1
6)
7print("Training (Strategy 2) finished.")
8if history_s2 and history_s2.history.get('val_loss'):
9 print(f"S2 - Final validation loss: {history_s2.history['val_loss'][-1]:.4f}")
Step 2.4: Prediction & Visualization (Strategy 2)¶
The prediction and visualization process is identical to Strategy 1, using model_s2.
1print("\nMaking predictions with Strategy 2 model...")
2predictions_scaled_s2 = model_s2.predict(val_inputs, verbose=0)
3print(f"Prediction output shape (Strategy 2): {predictions_scaled_s2.shape}")
4
5# --- Inverse Transform (Example) ---
6target_scaler_s2 = scalers_anom.get(target_col_anom)
7if target_scaler_s2:
8 num_val_s2 = val_inputs[0].shape[0] if val_inputs[0] is not None \
9 else val_inputs[1].shape[0]
10 num_q_s2 = len(quantiles_anom)
11 output_dim_s2 = 1 # Assuming univariate
12
13 pred_reshaped_s2 = predictions_scaled_s2.reshape(-1, num_q_s2 * output_dim_s2)
14 if output_dim_s2 == 1: # Common case
15 predictions_inv_s2 = target_scaler_s2.inverse_transform(pred_reshaped_s2)
16 predictions_final_s2 = predictions_inv_s2.reshape(
17 num_val_s2, forecast_horizons_anom, num_q_s2
18 )
19 # y_val was already inverse transformed for Strategy 1 if target_scaler_s1 existed
20 # Assuming y_val_final_s1 is available from Strategy 1 for comparison
21 # If not, inverse transform y_val here using target_scaler_s2
22 y_val_final_s2 = y_val_final_s1 # Re-use if scaler is the same
23 print("Predictions inverse transformed for Strategy 2.")
24 else:
25 print("Inverse transform for multi-output quantiles for S2 not shown.")
26 predictions_final_s2 = predictions_scaled_s2
27 y_val_final_s2 = y_val # Plot scaled if multi-output inverse is complex
28else:
29 print("Warning: Target scaler not found for Strategy 2. Plotting scaled values.")
30 predictions_final_s2 = predictions_scaled_s2
31 y_val_final_s2 = y_val # Plot scaled
32
33# --- Visualization (Example for one sample) ---
34if predictions_final_s2 is not None and y_val_final_s2 is not None:
35 sample_to_plot_s2 = 0
36 actual_vals_s2 = y_val_final_s2[sample_to_plot_s2, :, 0]
37 pred_quantiles_s2 = predictions_final_s2[sample_to_plot_s2, :, :]
38 time_axis_s2 = np.arange(forecast_horizons_anom)
39
40 plt.figure(figsize=(10, 5))
41 plt.plot(time_axis_s2, actual_vals_s2, label='Actual Sales', marker='o', linestyle='--')
42 plt.plot(time_axis_s2, pred_quantiles_s2[:, 1], label='Median Forecast (q=0.5)', marker='x')
43 plt.fill_between(
44 time_axis_s2, pred_quantiles_s2[:, 0], pred_quantiles_s2[:, 2],
45 color='orange', alpha=0.3, label='Interval (q0.1-q0.9) - Strategy 2'
46 )
47 plt.title(f'XTFT Quantile Forecast (Strategy 2 - Sample {sample_to_plot_s2})')
48 plt.xlabel('Forecast Step'); plt.ylabel('Sales')
49 plt.legend(); plt.grid(True); plt.tight_layout()
50 # plt.savefig(os.path.join(output_dir_xtft_anom, "s2_forecast_plot.png"))
51 plt.show()
52 print("Strategy 2: Plot generated.")
53else:
54 print("Strategy 2: Skipping plot due to missing prediction/actual data.")
55
56 # [Out] Training (Strategy 2) finished.
57 # S2 - Final validation loss: 0.7625
Example Output Plot (Conceptual):
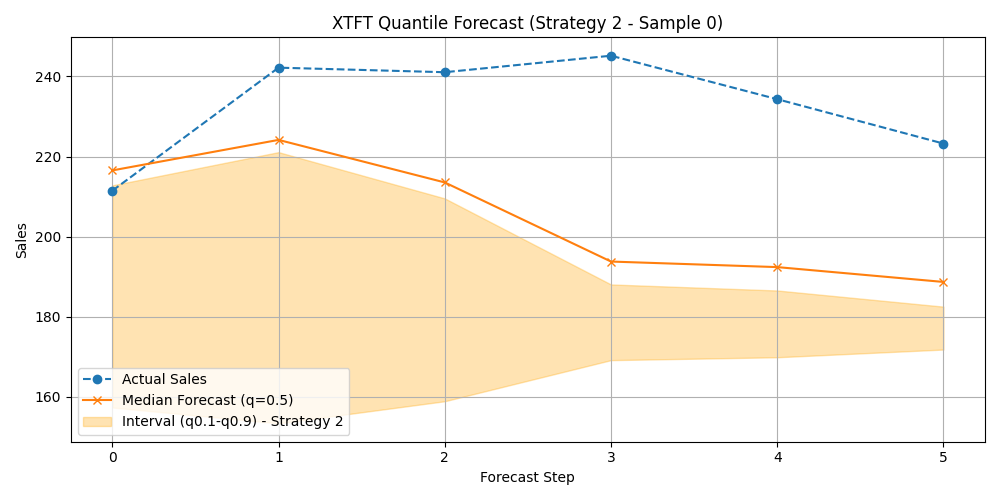
Conceptual visualization of XTFT quantile forecast where training incorporated an anomaly detection strategy.¶