Exercise: A Basic PIHALNet Forecasting Workflow¶
Welcome to this exercise on using the
PIHALNet model, the flagship
Physics-Informed Neural Network in fusionlab-learn.
In this tutorial, we will walk through a complete end-to-end workflow for a point forecast (non-quantile). We will focus on the correct data preparation needed for a PINN, particularly ensuring that the model receives coordinate inputs that align with the prediction window (the forecast horizon). This is a critical concept for PINNs where the PDE residual is evaluated over the forecast domain.
Learning Objectives:
Generate synthetic spatio-temporal data with static, dynamic (past), and future known features.
Correctly structure the input data dictionary for
PIHALNet, ensuring thecoordsinput matches theforecast_horizon.Instantiate and compile a
PIHALNetmodel with a basic configuration.Train the model on the synthetic dataset for a few epochs.
Make predictions using the trained model.
Format the model’s output predictions into a pandas DataFrame.
Use the
forecast_view()utility to create a spatial visualization of the forecast results.
Let’s begin!
Prerequisites¶
Ensure you have fusionlab-learn and its core dependencies
installed. For visualizations, matplotlib is also required.
pip install fusionlab-learn matplotlib
Step 1: Imports and Setup¶
First, we import all necessary libraries for this exercise. We will use TensorFlow for the backend and NumPy for data generation.
1import os
2import numpy as np
3import pandas as pd
4import tensorflow as tf
5import warnings
6
7# FusionLab imports (adjust paths if necessary for your environment)
8from fusionlab.nn.pinn.models import PIHALNet
9from fusionlab.plot.forecast import forecast_view, plot_forecast_by_step
10from fusionlab.plot.forecast import plot_forecasts
11from tensorflow.keras.losses import MeanSquaredError
12from tensorflow.keras.optimizers import Adam
13from tensorflow.data import Dataset, AUTOTUNE
14
15# Suppress warnings and TF logs for cleaner output
16warnings.filterwarnings('ignore')
17tf.get_logger().setLevel('ERROR')
18
19# Directory for saving any output images from this exercise
20EXERCISE_OUTPUT_DIR = "./pihalnet_exercise_outputs"
21os.makedirs(EXERCISE_OUTPUT_DIR, exist_ok=True)
22
23print("Libraries imported and setup complete for PIHALNet exercise.")
Expected Output:
Libraries imported and setup complete for PIHALNet exercise.
Step 2: Define Configuration¶
We’ll define all our parameters in one place. This includes the data dimensions and the model’s fixed parameters. Note that we are setting time_steps to 5 and forecast_horizon to 7, a scenario that requires careful data handling.
1# Toy configuration for the exercise
2BATCH_SIZE = 4
3TIME_STEPS = 5 # Look-back window size
4FORECAST_HORIZON = 7 # Prediction window size (now > time_steps)
5STATIC_INPUT_DIM = 2
6DYNAMIC_INPUT_DIM = 3
7FUTURE_INPUT_DIM = 1
8RANDOM_SEED = 42
9
10np.random.seed(RANDOM_SEED)
11tf.random.set_seed(RANDOM_SEED)
12
13# Define the fixed parameters for our PIHALNet model
14fixed_model_params = {
15 "static_input_dim": STATIC_INPUT_DIM,
16 "dynamic_input_dim": DYNAMIC_INPUT_DIM,
17 "future_input_dim": FUTURE_INPUT_DIM,
18 "output_subsidence_dim": 1,
19 "output_gwl_dim": 1,
20 "forecast_horizon": FORECAST_HORIZON,
21 "quantiles": None, # We will do a point forecast
22 "max_window_size": TIME_STEPS,
23 "pde_mode": "consolidation",
24 "pinn_coefficient_C": "learnable",
25 "use_vsn": True
26}
27
28# Define some architectural parameters for the model
29architectural_params = {
30 "embed_dim": 16,
31 "hidden_units": 16,
32 "lstm_units": 16,
33 "attention_units": 8,
34 "num_heads": 2,
35 "dropout_rate": 0.1,
36 "activation": "relu"
37}
38print("Configuration set for PIHALNet exercise.")
Expected Output:
Configuration set for PIHALNet exercise.
Step 3: Generate Synthetic Data¶
Here, we generate toy data that mimics what the
prepare_pinn_data_sequences utility would produce. The most
important part is to create a separate coords tensor for the
forecast window, with a time dimension equal to forecast_horizon.
1# 1. Generate features for the lookback window (length = time_steps)
2static_features = np.random.rand(
3 BATCH_SIZE, STATIC_INPUT_DIM
4).astype("float32")
5dynamic_features = np.random.rand(
6 BATCH_SIZE, TIME_STEPS, DYNAMIC_INPUT_DIM
7).astype("float32")
8
9# 2. Generate features and coordinates for the FORECAST window
10# These are the coordinates where the PDE will be evaluated.
11# Their time dimension must match `forecast_horizon`.
12future_t_coords = np.tile(
13 np.arange(
14 FORECAST_HORIZON, dtype="float32"
15 ).reshape(1, FORECAST_HORIZON, 1),
16 (BATCH_SIZE, 1, 1)
17)
18future_x_coords = np.random.rand(
19 BATCH_SIZE, FORECAST_HORIZON, 1
20).astype("float32")
21future_y_coords = np.random.rand(
22 BATCH_SIZE, FORECAST_HORIZON, 1
23).astype("float32")
24
25# This is the CORRECT coordinates tensor for the model input dict
26forecast_coords = np.concatenate(
27 [future_t_coords, future_x_coords, future_y_coords], axis=-1
28)
29
30future_features = np.random.rand(
31 BATCH_SIZE, FORECAST_HORIZON, FUTURE_INPUT_DIM
32).astype("float32")
33
34# 3. Generate targets matching the forecast_horizon
35subs_targets = np.random.rand(
36 BATCH_SIZE, FORECAST_HORIZON, 1
37).astype("float32")
38gwl_targets = np.random.rand(
39 BATCH_SIZE, FORECAST_HORIZON, 1
40).astype("float32")
41
42# 4. Package inputs and targets into dictionaries
43inputs = {
44 "coords": forecast_coords, # Shape: (batch, forecast_horizon, 3)
45 "static_features": static_features,
46 "dynamic_features": dynamic_features,
47 "future_features": future_features,
48}
49targets = {
50 "subs_pred": subs_targets,
51 "gwl_pred": gwl_targets,
52}
53
54# 5. Create a tf.data.Dataset
55dataset = Dataset.from_tensor_slices((inputs, targets)).batch(BATCH_SIZE)
56
57print("Synthetic data generated and packaged into tf.data.Dataset.")
58print(f"Shape of inputs['coords']: {inputs['coords'].shape}")
59print(f"Shape of inputs['dynamic_features']: {inputs['dynamic_features'].shape}")
60print(f"Shape of inputs['future_features']: {inputs['future_features'].shape}")
Expected Output:
Synthetic data generated and packaged into tf.data.Dataset.
Shape of inputs['coords']: (4, 7, 3)
Shape of inputs['dynamic_features']: (4, 5, 3)
Shape of inputs['future_features']: (4, 7, 1)
Step 4: Instantiate and Compile PIHALNet¶
Now, we create an instance of PIHALNet using our defined parameters
and compile it with an optimizer and loss functions.
1# Instantiate PIHALNet with both fixed and architectural params
2model = PIHALNet(**fixed_model_params, **architectural_params)
3
4# Compile the model
5model.compile(
6 optimizer=Adam(learning_rate=1e-3, clipnorm=1.0),
7 loss={
8 "subs_pred": MeanSquaredError(name="subs_data_loss"),
9 "gwl_pred": MeanSquaredError(name="gwl_data_loss"),
10 },
11 metrics={
12 "subs_pred": ["mae"],
13 "gwl_pred": ["mae"],
14 },
15 loss_weights={"subs_pred": 1.0, "gwl_pred": 0.8},
16 lambda_pde=0.1 # Weight for the physics loss component
17)
18
19# Build the model to see the summary (optional, fit() will also build it)
20model.build(input_shape={k: v.shape for k, v in inputs.items()})
21model.summary(line_length=110)
Expected Output:
Model: "PIHALNet"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
... (a long list of PIHALNet's internal layers) ...
=================================================================
Total params: 13266 (51.82 KB)
Trainable params: 13266 (51.82 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Step 5: Train the PIHALNet Model¶
We will now train the model for a few epochs. Since we have a custom train_step in PIHALNet, we can see the breakdown of the total loss into data_loss and physics_loss.
1print("\nStarting model training for 3 epochs...")
2history = model.fit(dataset, epochs=50, verbose=1)
3print("\nModel training finished.")
Expected Output:
Starting model training for 3 epochs...
Epoch 1/50
1/1 [==============================] - 14s 14s/step - loss: 3.2426 - gwl_pred_loss: 1.4587 - subs_pred_loss: 2.0757 - gwl_pred_mae: 1.0282 - subs_pred_mae: 1.1943 - total_loss: 3.7428 - data_loss: 3.2426 - physics_loss: 5.0017
Epoch 2/50
1/1 [==============================] - 0s 19ms/step - loss: 2.8974 - gwl_pred_loss: 1.1237 - subs_pred_loss: 1.9985 - gwl_pred_mae: 0.9409 - subs_pred_mae: 1.1585 - total_loss: 3.0105 - data_loss: 2.8974 - physics_loss: 1.1308
...
Epoch 50/50
1/1 [==============================] - 0s 14ms/step - loss: 0.6317 - gwl_pred_loss: 0.4577 - subs_pred_loss: 0.2656 - gwl_pred_mae: 0.5523 - subs_pred_mae: 0.4584 - total_loss: 0.6387 - data_loss: 0.6317 - physics_loss: 0.0702
Model training finished.
Step 6: Visualize Training History¶
Use the plot_history_in utility to visualize the loss curves.
1from fusionlab.nn.models.utils import plot_history_in
2print("\\nPlotting training history...")
3
4pihalnet_metrics = {
5 "Loss Components": ["total_loss", "data_loss", "physics_loss"],
6 "Subsidence MAE": ["subs_pred_mae", "gwl_pred_mae"]
7}
8plot_history_in(
9 history,
10 metrics=pihalnet_metrics,
11 layout='subplots',
12 title='PIHALNet Training History'
13 )
Example Output Plot:
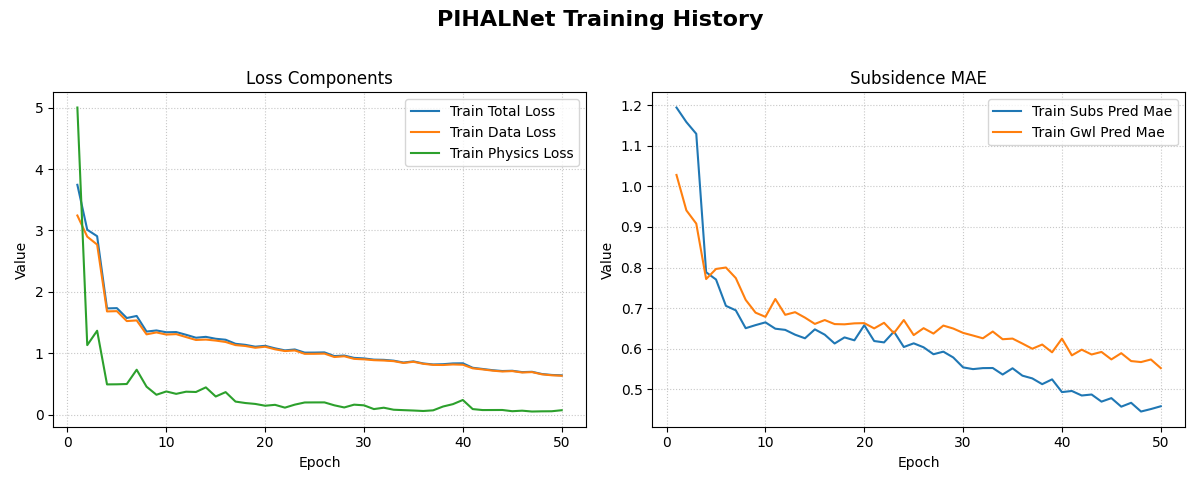
An example plot showing the training and validation loss and Mean Absolute Error (MAE) over epochs. This helps in diagnosing model fit and convergence.¶
In many cases you will want to monitor how well the network generalises
while it trains.
Below we create a second PIHALNet instance (model_val), split the
synthetic dataset into an 80 / 20 train‑validation split, run
model.fit with the validation_data argument, and finally plot both
training and validation curves.
1# 1. Prepare an explicit train / validation split
2from tensorflow.data import AUTOTUNE
3
4total_batches = int(
5 tf.data.experimental.cardinality(dataset).numpy()
6)
7if total_batches < 2:
8 # Not enough batches to split → fall back to 1 batch train + 1 batch val
9 warnings.warn(
10 "Dataset has a single batch; duplicating it for validation.",
11 RuntimeWarning,
12 )
13 train_ds = dataset
14 valid_ds = dataset.take(1).prefetch(AUTOTUNE)
15else:
16 val_batches = max(1, int(0.2 * total_batches)) # 20 % → validation
17 train_ds = dataset.take(total_batches - val_batches)
18 valid_ds = dataset.skip(total_batches - val_batches).prefetch(AUTOTUNE)
19
20# 2. Instantiate a new PIHALNet model (identical hyper‑params)
21model_val = PIHALNet(**fixed_model_params, **architectural_params)
22
23model_val.compile(
24 optimizer=Adam(learning_rate=1e-3, clipnorm=1.0),
25 loss={
26 "subs_pred": MeanSquaredError(name="subs_data_loss"),
27 "gwl_pred": MeanSquaredError(name="gwl_data_loss"),
28 },
29 metrics={
30 "subs_pred": ["mae"],
31 "gwl_pred": ["mae"],
32 },
33 loss_weights={"subs_pred": 1.0, "gwl_pred": 0.8},
34 lambda_pde=0.1,
35)
36
37# 3. Fit with validation_data; keep the History object
38print("\nTraining model with validation monitoring...")
39history_val = model_val.fit(
40 train_ds,
41 validation_data=valid_ds,
42 epochs=50,
43 verbose=1,
44)
45print("\nTraining finished.")
46
47# 4. Plot both training and validation curves
48from fusionlab.nn.models.utils import plot_history_in
49
50print("\nPlotting training + validation history ...")
51
52# Extend the metric groups to include their 'val_' counterparts
53pihalnet_metrics_val = {
54 "Loss Components": [
55 "loss", "total_loss", "data_loss", "physics_loss",
56 "val_loss",'val_gwl_pred_loss', 'val_subs_pred_loss'
57 ],
58 "Subsidence MAE": [
59 "subs_pred_mae", "gwl_pred_mae",
60 "val_subs_pred_mae", "val_gwl_pred_mae",
61 ]
62}
63
64plot_history_in(
65 history_val,
66 metrics=pihalnet_metrics_val,
67 layout="subplots",
68 title="PIHALNet Train & Valid History",
69)
Example Output Plot:
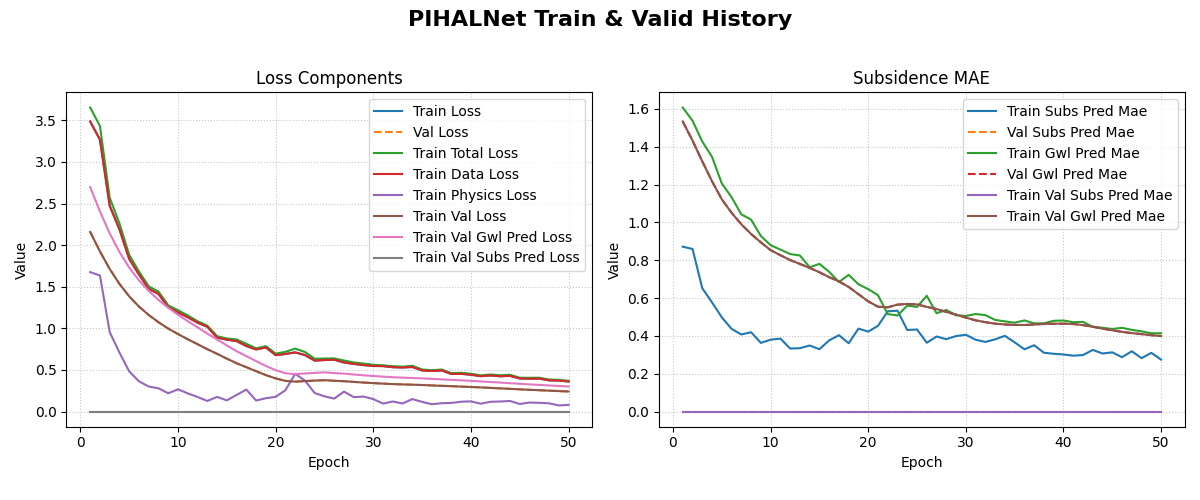
An example plot showing the training and validation loss and Mean Absolute Error (MAE) over epochs.¶
What you should see
Left panel – total, data, and physics losses for both training (solid) and validation (dashed) sets.
Right panel – MAE for subsidence and GWL; dashed curves represent validation MAE.
A widening gap between the solid and dashed curves would indicate over‑fitting; closely tracking curves suggest good generalisation.
Step 7: Make Predictions and Format for Visualization¶
After training, we use model.predict() and then structure the results into a long-format DataFrame suitable for forecast_view.
1print("\nMaking predictions on the training data...")
2predictions = model.predict(dataset)
3
4# The output is a dictionary: {'subs_pred': ..., 'gwl_pred': ...}
5# Let's format this into a pandas DataFrame.
6
7# We will manually create the DataFrame for this exercise.
8# In a real application, you might use a utility like
9# `format_pihalnet_predictions`qqq.
10# from fusionlab.nn.pinn.utils import format_pihalnet_predictions
11# df_results = format_pihalnet_predictions (predictions)
12
13all_rows = []
14for i in range(BATCH_SIZE): # Iterate through each sample in the batch
15 for j in range(FORECAST_HORIZON): # Iterate through each forecast step
16 row = {
17 'sample_idx': i,
18 'forecast_step': j + 1,
19 'coord_t': inputs['coords'][i, j, 0],
20 'coord_x': inputs['coords'][i, j, 1],
21 'coord_y': inputs['coords'][i, j, 2],
22 'subsidence_pred': predictions['subs_pred'][i, j, 0],
23 'subsidence_actual': targets['subs_pred'][i, j, 0],
24 'GWL_pred': predictions['gwl_pred'][i, j, 0],
25 'GWL_actual': targets['gwl_pred'][i, j, 0]
26 }
27 all_rows.append(row)
28
29df_results = pd.DataFrame(all_rows)
30print("\nFormatted prediction DataFrame (first 5 rows):")
31print(df_results.head())
Expected Output:
Making predictions on the training data...
1/1 [==============================] - 0s 12ms/step
Formatted prediction DataFrame (first 5 rows):
sample_idx forecast_step coord_t ... subsidence_actual GWL_pred GWL_actual
0 0 1 0.0 ... 0.144895 0.234190 0.341066
1 0 2 1.0 ... 0.489453 -0.349084 0.113474
2 0 3 2.0 ... 0.985650 0.326578 0.924694
3 0 4 3.0 ... 0.242055 0.388380 0.877339
4 0 5 4.0 ... 0.672136 0.464236 0.257942
[5 rows x 9 columns]
Step 7: Visualize the Forecast¶
Finally, we use forecast_view to visualize the spatial distribution of our predictions and compare them with the actuals.
1print("\nVisualizing forecasts for 'subsidence'...")
2plot_forecasts(
3 forecast_df=df_results,
4 target_name='subsidence', # We only plot subsidence
5 kind='spatial',
6 spatial_cols=('coord_x', 'coord_y'),
7 dt_col='coord_t',
8 horizon_steps = [1, 2, 3],
9 max_cols=3, # Display 'Prediction' side-by-side
10 cmap='viridis',
11 axis_off=False,
12 savefig=os.path.join(EXERCISE_OUTPUT_DIR, "pihalnet_exercise_forecast.png"),
13 verbose=1
14)
15
16# we can use plot_forecast_by_step
17from fusionlab.nn.pinn.utils import format_pihalnet_predictions
18from fusionlab.plot.forecast import plot_forecast_by_step
19
20# df_results = format_pihalnet_predictions (predictions)
21# plot_forecast_by_step(df_results, steps = [1, 2, 3], value_prefixes =['subsidence'])
Expected Output:
Visualizing forecasts for 'subsidence'...
[INFO] Starting forecast visualization (kind='spatial')...
[INFO] Plotting for sample_idx: [0 1 2]
[INFO] Forecast visualization complete.
Expected Plot:

A grid of plots showing the spatial distribution of actual subsidence vs. predicted subsidence for each step in the forecast horizon.¶
Discussion of Exercise¶
In this exercise, you successfully:
Configured and instantiated a complex PIHALNet model.
Generated synthetic data that correctly separates past inputs (dynamic features) from the future prediction window (coords, future features, targets).
Understood the importance of providing the model with coords that have a time dimension equal to the forecast_horizon.
Trained the model and observed the data and physics loss components.
Formatted predictions into a DataFrame and used forecast_view to visualize the results.
This workflow provides a solid foundation for applying PIHALNet and its associated tools to real-world spatio-temporal forecasting problems.